

🚨 DeepMind discovered that neural networks can train for thousands of epochs without learning anything.
Then suddenly, in a single epoch, they generalize perfectly.
This phenomenon is called "Grokking".
It went from a weird training glitch to a core theory of how models actually learn.
Here’s what changed (and why this matters now):
Then suddenly, in a single epoch, they generalize perfectly.
This phenomenon is called "Grokking".
It went from a weird training glitch to a core theory of how models actually learn.
Here’s what changed (and why this matters now):
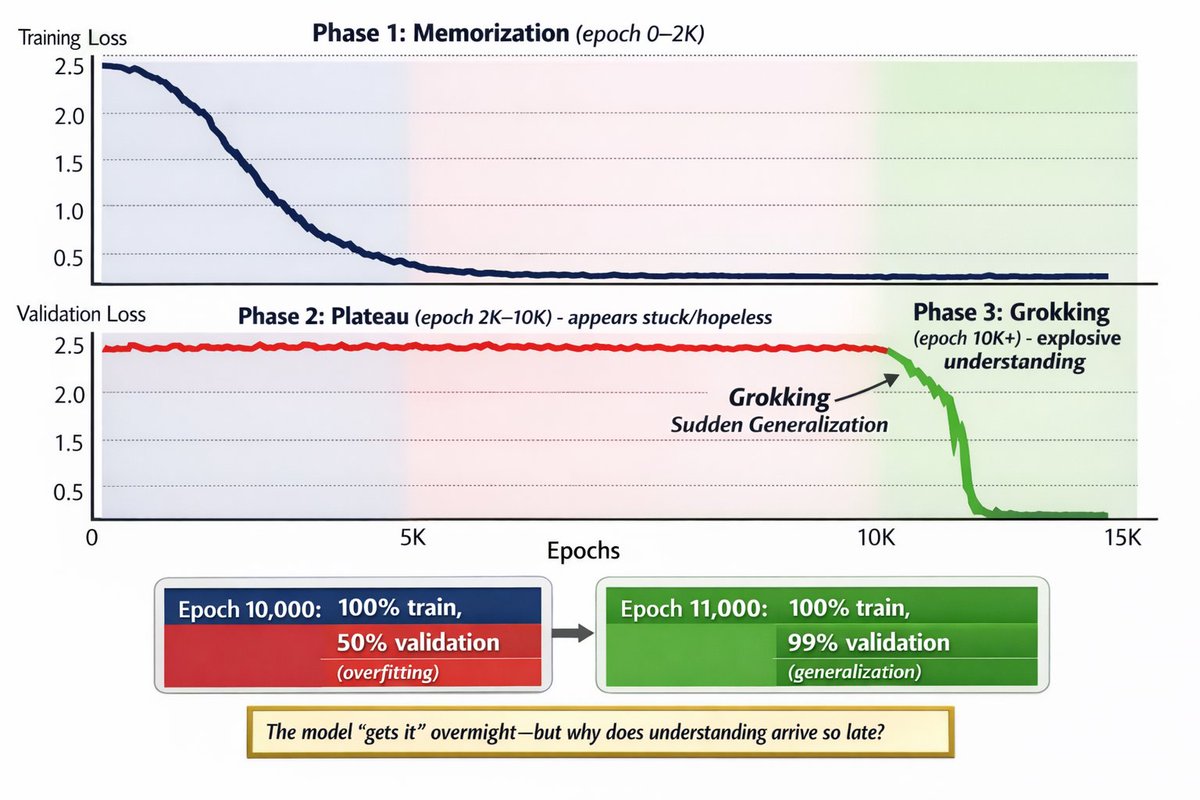
Grokking was discovered by accident in 2022.
Researchers at OpenAI trained models on simple math tasks (modular addition, permutation groups). Standard training: Model overfits fast, generalizes poorly.
But when they kept training past "convergence" 10,000+ epochs models suddenly achieved perfect generalization.
Nobody expected this.
Researchers at OpenAI trained models on simple math tasks (modular addition, permutation groups). Standard training: Model overfits fast, generalizes poorly.
But when they kept training past "convergence" 10,000+ epochs models suddenly achieved perfect generalization.
Nobody expected this.

Why this is wild:
Traditional ML wisdom: "If validation loss doesn't improve for 100 epochs, stop training (early stopping)."
Grokking says: "Keep going for 10,000 more epochs. Understanding is coming you just can't see it yet."
It completely breaks our intuition about when learning happens.
Traditional ML wisdom: "If validation loss doesn't improve for 100 epochs, stop training (early stopping)."
Grokking says: "Keep going for 10,000 more epochs. Understanding is coming you just can't see it yet."
It completely breaks our intuition about when learning happens.
What's actually happening during the plateau?
The model isn't stuck. It's reorganizing its internal representations.
During 10,000 "useless" epochs:
→ Circuits form and dissolve
→ Weight patterns crystallize
→ Spurious correlations get pruned
→ True structure emerges
It's like insight in humans. Slow, then sudden.
The model isn't stuck. It's reorganizing its internal representations.
During 10,000 "useless" epochs:
→ Circuits form and dissolve
→ Weight patterns crystallize
→ Spurious correlations get pruned
→ True structure emerges
It's like insight in humans. Slow, then sudden.
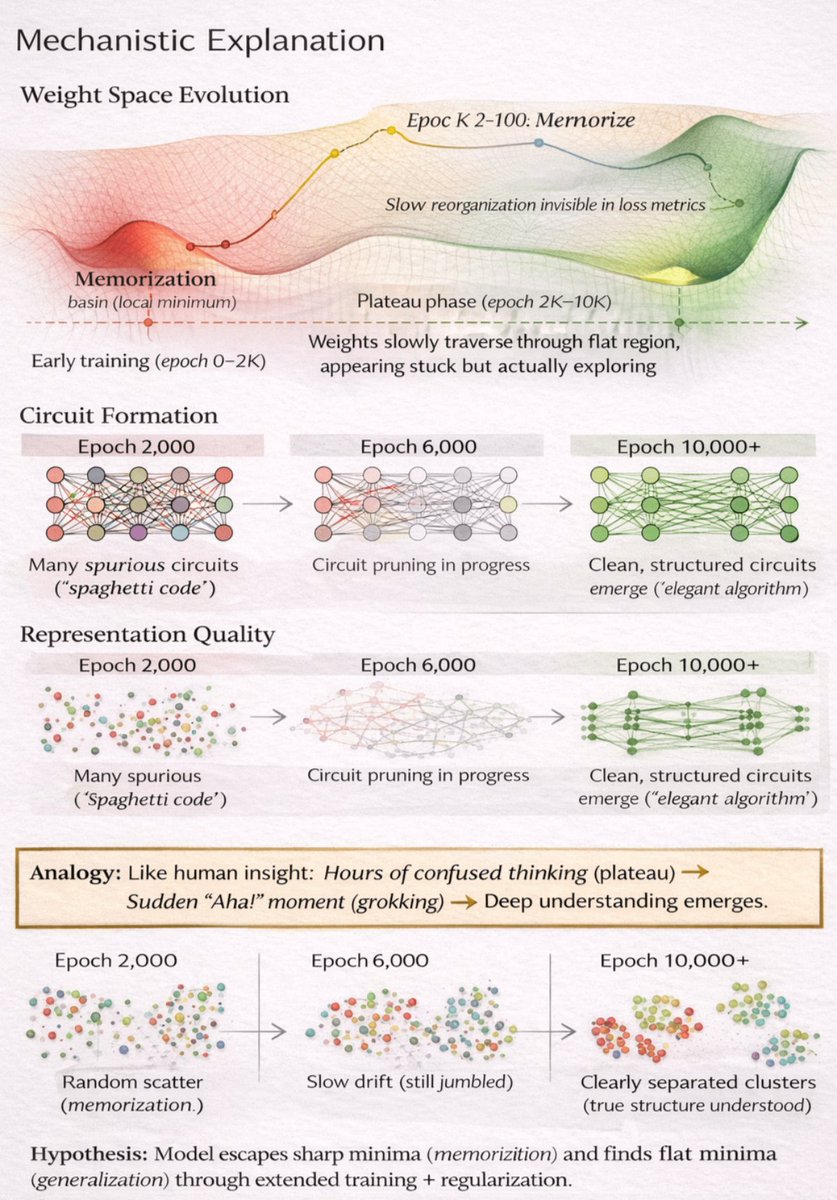
The factors that trigger grokking:
✅ Weight decay (L2 regularization) critical
✅ Data scarcity (forces model to find true patterns)
✅ Overparameterization (model needs excess capacity)
✅ Prolonged training (patience required)
✅ Right optimizer (AdamW works better than SGD)
Without these? Model stays stuck in memorization forever.
✅ Weight decay (L2 regularization) critical
✅ Data scarcity (forces model to find true patterns)
✅ Overparameterization (model needs excess capacity)
✅ Prolonged training (patience required)
✅ Right optimizer (AdamW works better than SGD)
Without these? Model stays stuck in memorization forever.
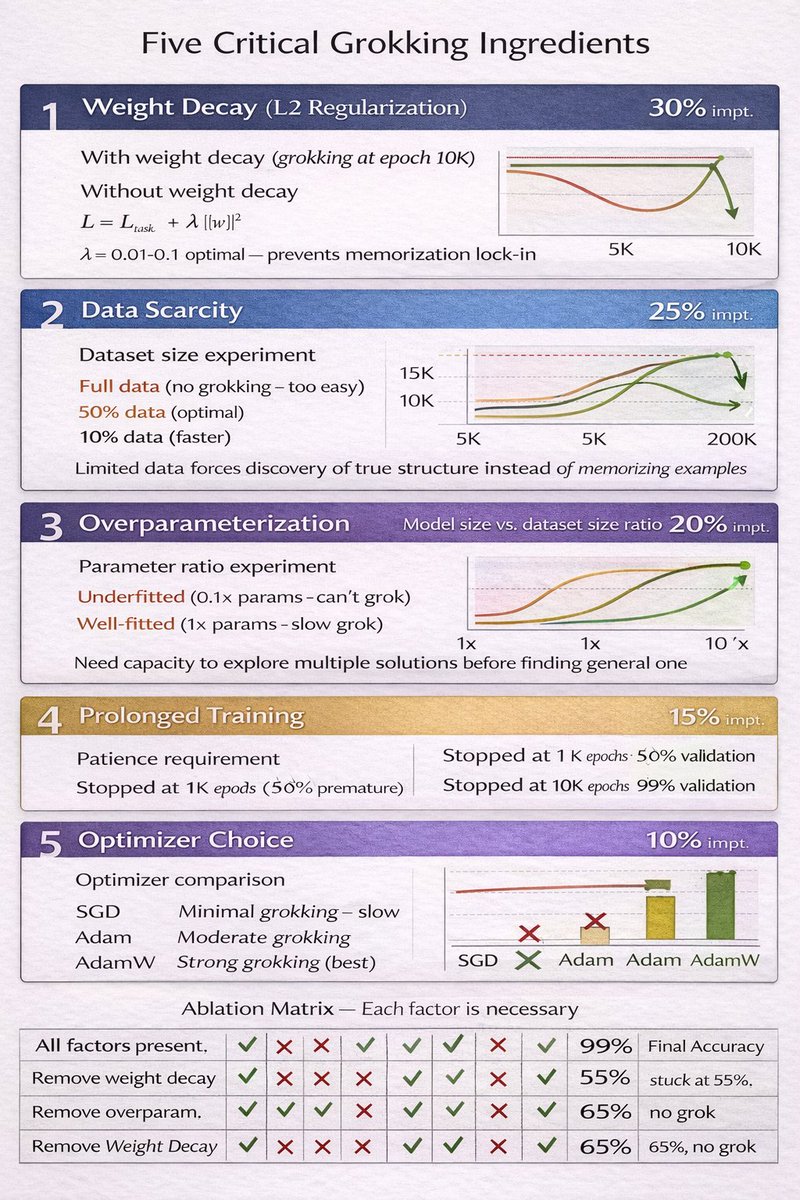
Real example from the paper:
Task: Learn modular addition (e.g., 5 + 7 = 1 mod 11)
Training data: 30% of all possible combinations
Model: 2-layer MLP with 512 hidden units
Epoch 500: 100% train accuracy, 50% validation (memorized examples)
Epoch 10,000: Still 50% validation (looks hopeless)
Epoch 12,000: Suddenly 99% validation (grokked the modular arithmetic rule)
Task: Learn modular addition (e.g., 5 + 7 = 1 mod 11)
Training data: 30% of all possible combinations
Model: 2-layer MLP with 512 hidden units
Epoch 500: 100% train accuracy, 50% validation (memorized examples)
Epoch 10,000: Still 50% validation (looks hopeless)
Epoch 12,000: Suddenly 99% validation (grokked the modular arithmetic rule)
Why this matters for 2026:
Grokking explains why some fine-tuning runs suddenly "click" after seeming stuck.
It's happening in:
→ RLHF training (models grok human preferences)
→ Domain adaptation (medical/legal LLMs)
→ Reasoning models (o1, DeepSeek-R1)
Those "train longer" experiments? They're inducing grokking at scale.
Grokking explains why some fine-tuning runs suddenly "click" after seeming stuck.
It's happening in:
→ RLHF training (models grok human preferences)
→ Domain adaptation (medical/legal LLMs)
→ Reasoning models (o1, DeepSeek-R1)
Those "train longer" experiments? They're inducing grokking at scale.

Grokking and prompt engineering:
If models grok during training, can we induce grokking at inference?
Emerging techniques:
→ "Think for 10,000 tokens" (extended CoT)
→ Self-consistency sampling (multiple reasoning paths)
→ Verification loops (like CoVe)
We're teaching models to grok problems on-demand.
If models grok during training, can we induce grokking at inference?
Emerging techniques:
→ "Think for 10,000 tokens" (extended CoT)
→ Self-consistency sampling (multiple reasoning paths)
→ Verification loops (like CoVe)
We're teaching models to grok problems on-demand.
How to induce grokking in your models:
1. Don't stop training when validation plateaus
2. Add weight decay (λ=0.01 to 0.1)
3. Use AdamW optimizer
4. Train with limited data (counterintuitively)
5. Be patient (10-100x normal training time)
Warning: Expensive. But if you need perfect generalization, grokking is the only path.
1. Don't stop training when validation plateaus
2. Add weight decay (λ=0.01 to 0.1)
3. Use AdamW optimizer
4. Train with limited data (counterintuitively)
5. Be patient (10-100x normal training time)
Warning: Expensive. But if you need perfect generalization, grokking is the only path.
Grokking proves that understanding isn't monotonic. It's discontinuous.
Models don't gradually get smarter. They stay dumb for 10,000 epochs, then suddenly "get it."
This changes everything:
→ When to stop training
→ How to design curricula
→ What "learning" even means
The plateau before the breakthrough. The patience before the insight.
Grokking is the most human thing about neural networks.
Models don't gradually get smarter. They stay dumb for 10,000 epochs, then suddenly "get it."
This changes everything:
→ When to stop training
→ How to design curricula
→ What "learning" even means
The plateau before the breakthrough. The patience before the insight.
Grokking is the most human thing about neural networks.
That's a wrap:
I hope you've found this thread helpful.
Follow me @godofprompt for more.
Like/Repost the quote below if you can:
I hope you've found this thread helpful.
Follow me @godofprompt for more.
Like/Repost the quote below if you can:
جاري تحميل الاقتراحات...