

إذا كنت مهتم بمجال الـMachine Learning، فـPreprocessing يعتبر الأساس لأي نموذج ناجح!⚡️
في هذا الثريد، أوضّح أهم مفاهيمه وكيف يؤثر مباشرة على أداء النموذج.
إذا الوقت ما يسمح الحين، احفظ التغريدة وارجع لها متى ما احتجت.🫡🔥 x.com
في هذا الثريد، أوضّح أهم مفاهيمه وكيف يؤثر مباشرة على أداء النموذج.
إذا الوقت ما يسمح الحين، احفظ التغريدة وارجع لها متى ما احتجت.🫡🔥 x.com
قبل لا ندخل في التفاصيل، خلونا نفهم ليش كل هذا مهم. البيانات الخام غالبًا تكون غير جاهزة للنماذج، فيها قيم مفقودة، أو نصوص ما تفهمها الخوارزميات، أو بيانات مو مقسمة صح. تجهيزها هو أول خطوة لنموذج ناجح.
وبنتكلم أيضا عن أهمية التعامل مع Categorical data وكيف تحويلها لأرقام يساعد النماذج. وأيضًا ليش تقسيم البيانات للتدريب والاختبار خطوة لا غنى عنها. خلونا نبدأ… 👇
وبنتكلم أيضا عن أهمية التعامل مع Categorical data وكيف تحويلها لأرقام يساعد النماذج. وأيضًا ليش تقسيم البيانات للتدريب والاختبار خطوة لا غنى عنها. خلونا نبدأ… 👇
القيم المفقودة (NaN): الكابوس الأكبر في أي مشروع بيانات!
- سواء كانت بسبب أخطاء في جمع البيانات، استبيانات ناقصة، أو معلومات غير قابلة للقياس، القيم المفقودة تعتبر مشكلة شائعة جدًا.
الخطر؟
- الأدوات التحليلية ما تقدر تتعامل مع القيم المفقودة بشكل صحيح، ولو تجاهلتها؟ ممكن تحصل على نتائج غير دقيقة أو غامضة😱
- سواء كانت بسبب أخطاء في جمع البيانات، استبيانات ناقصة، أو معلومات غير قابلة للقياس، القيم المفقودة تعتبر مشكلة شائعة جدًا.
الخطر؟
- الأدوات التحليلية ما تقدر تتعامل مع القيم المفقودة بشكل صحيح، ولو تجاهلتها؟ ممكن تحصل على نتائج غير دقيقة أو غامضة😱
أول خطوة: اكتشف القيم المفقودة
ما تقدر تعالج المشكلة إذا ما عرفت وينها.
الحل؟
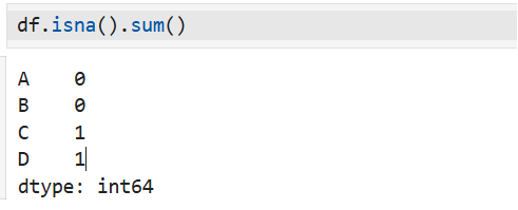
استخدم isnull مع sum عشان تشوف عدد القيم المفقودة في كل عمود،
كما هو موضح في الكود:🪄
()isna : يتحقق من وجود القيم المفقودة في كل خلية ويُرجع True إذا كانت القيمة مفقودة.
()sum : يجمع عدد القيم المفقودة لكل عمود.
النتيجة:
A,B : لا توجد قيم مفقودة
C : قيمة مفقودة واحدة
D : قيمة مفقودة واحدة
ما تقدر تعالج المشكلة إذا ما عرفت وينها.
الحل؟
استخدم isnull مع sum عشان تشوف عدد القيم المفقودة في كل عمود،
كما هو موضح في الكود:🪄
()isna : يتحقق من وجود القيم المفقودة في كل خلية ويُرجع True إذا كانت القيمة مفقودة.
()sum : يجمع عدد القيم المفقودة لكل عمود.
النتيجة:
A,B : لا توجد قيم مفقودة
C : قيمة مفقودة واحدة
D : قيمة مفقودة واحدة
حذف القيم المفقودة (Elimination) الحل السهل والسريع!
-إذا عندك بيانات فيها قيم مفقودة (NaN)، ممكن ببساطة تحذف الصفوف أو الأعمدة اللي فيها،
متى ينفع؟
- لو القيم المفقودة قليلة وما بتأثر على جودة البيانات.
إيجابيات:
- سريع وسهل.
- يحافظ على نظافة البيانات.
سلبيات:
- ممكن تفقد بيانات مهمة.
- لو القيم المفقودة كثيرة، النتائج بتتأثر.
"نصيحة: إذا القيم المفقودة موزعة بشكل كبير، جرب الإكمال (Imputation) بدل الحذف! 🤝"
-إذا عندك بيانات فيها قيم مفقودة (NaN)، ممكن ببساطة تحذف الصفوف أو الأعمدة اللي فيها،
متى ينفع؟
- لو القيم المفقودة قليلة وما بتأثر على جودة البيانات.
إيجابيات:
- سريع وسهل.
- يحافظ على نظافة البيانات.
سلبيات:
- ممكن تفقد بيانات مهمة.
- لو القيم المفقودة كثيرة، النتائج بتتأثر.
"نصيحة: إذا القيم المفقودة موزعة بشكل كبير، جرب الإكمال (Imputation) بدل الحذف! 🤝"
كيف تحذف القيم المفقودة باستخدام Pandas ؟
كما هو موضح في الكود:
dropna: تحذف القيم المفقودة من الـ DataFrame.
axis=0: تحذف الصفوف التي تحتوي على أي قيمة NaN
axis=1: تحذف الأعمدة التي تحتوي على أي قيمة NaN
how='all': تحذف الصفوف التي جميع قيمها NaN فقط.
['subset=['C: تحذف الصفوف بناءً على وجود قيم مفقودة في العمود "C" فقط.
استخدام هذه الطريقة مناسب لتنظيف البيانات بسرعة وسهولة!😁🪄
كما هو موضح في الكود:
dropna: تحذف القيم المفقودة من الـ DataFrame.
axis=0: تحذف الصفوف التي تحتوي على أي قيمة NaN
axis=1: تحذف الأعمدة التي تحتوي على أي قيمة NaN
how='all': تحذف الصفوف التي جميع قيمها NaN فقط.
['subset=['C: تحذف الصفوف بناءً على وجود قيم مفقودة في العمود "C" فقط.
استخدام هذه الطريقة مناسب لتنظيف البيانات بسرعة وسهولة!😁🪄

معالجة القيم المفقودة (Imputation) الحل الذكي بدال الحذف
إذا حذف الصفوف أو الأعمدة مو خيار مناسب لانك ممكن تخسر بيانات مهمة، جرب تعويض القيم المفقودة (NaN) باستخدام Imputation Techniques مثل:
Mean Imputation: استبدال القيم المفقودة بمتوسط العمود.
Median: استبدال القيم المفقودة بالقيمة الوسطى.
Most Frequent: استبدال القيم المفقودة بالقيمة الأكثر تكرارًا.
ليش مهم؟
- يحافظ على حجم البيانات.
- مفيد للقيم الرقمية والفئوية. (Categorical)
إذا حذف الصفوف أو الأعمدة مو خيار مناسب لانك ممكن تخسر بيانات مهمة، جرب تعويض القيم المفقودة (NaN) باستخدام Imputation Techniques مثل:
Mean Imputation: استبدال القيم المفقودة بمتوسط العمود.
Median: استبدال القيم المفقودة بالقيمة الوسطى.
Most Frequent: استبدال القيم المفقودة بالقيمة الأكثر تكرارًا.
ليش مهم؟
- يحافظ على حجم البيانات.
- مفيد للقيم الرقمية والفئوية. (Categorical)
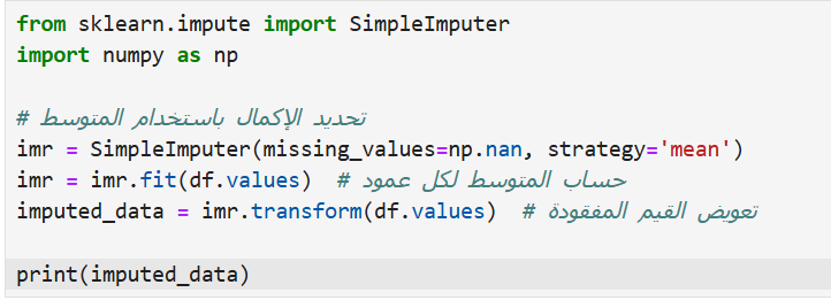
كما هو موضّح في الكود:
' strategy='mean : يحسب المتوسط لكل عمود ويعوض القيم المفقودة.
()fit : يتعلم من البيانات لحساب القيم المناسبة.
()transform : يطبق الـ Imputation على البيانات. x.com
' strategy='mean : يحسب المتوسط لكل عمود ويعوض القيم المفقودة.
()fit : يتعلم من البيانات لحساب القيم المناسبة.
()transform : يطبق الـ Imputation على البيانات. x.com
ولو تبي حل بسيط وسريع، استخدم Pandas مباشرة:
بهذا الشكل تعوض القيم المفقودة بالمتوسط بكل سهولة! ✔🔥 x.com
بهذا الشكل تعوض القيم المفقودة بالمتوسط بكل سهولة! ✔🔥 x.com

وش المقصود بـ Data Encoding؟🤔
Data Encoding يعني تحويل البيانات التصنيفية (Categorical Variables) إلى صيغة رقمية عشان النماذج تفهمها.
ليش؟ لأن خوارزميات تعلم الآلة تعتمد على العمليات الرياضية والإحصائية وما تفهم النصوص مباشرة. x.com
Data Encoding يعني تحويل البيانات التصنيفية (Categorical Variables) إلى صيغة رقمية عشان النماذج تفهمها.
ليش؟ لأن خوارزميات تعلم الآلة تعتمد على العمليات الرياضية والإحصائية وما تفهم النصوص مباشرة. x.com

ليش نحتاج Encoding؟
إذا عندك بيانات مثل:
- الألوان: 'red', 'green', 'blue'
- المقاسات: 'Small', 'Medium', 'Large'
- ما راح تفهمها النماذج إلا إذا حولناها لأرقام.
كيف؟
باستخدام تقنيات مثل:
Label Encoding : يعطي رقم لكل فئة بدون ترتيب.
Ordinal Encoding : يحول القيم مع احترام الترتيب.
One-Hot Encoding : يحول كل فئة إلى عمود مستقل (ثنائي).
إذا عندك بيانات مثل:
- الألوان: 'red', 'green', 'blue'
- المقاسات: 'Small', 'Medium', 'Large'
- ما راح تفهمها النماذج إلا إذا حولناها لأرقام.
كيف؟
باستخدام تقنيات مثل:
Label Encoding : يعطي رقم لكل فئة بدون ترتيب.
Ordinal Encoding : يحول القيم مع احترام الترتيب.
One-Hot Encoding : يحول كل فئة إلى عمود مستقل (ثنائي).
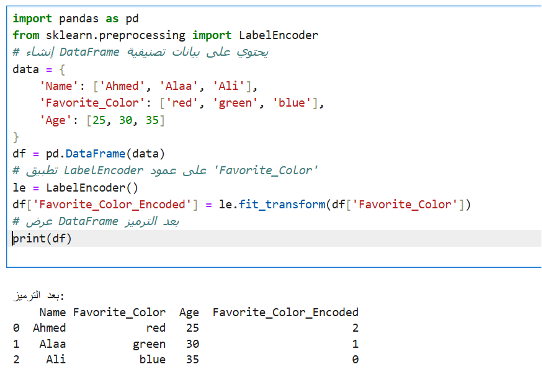
Label Encoding:
- في هذا الكود، قمنا بتحويل عمود Favorite_Color من قيم نصية (red, green, blue) إلى أرقام باستخدام LabelEncoder.
- fit_transform: يحول القيم النصية إلى أرقام مميزة لكل فئة.
- red = 2
- green = 1
- blue = 0
النتيجة:
DataFrame يحتوي على العمود الأصلي مع عمود جديد (Favorite_Color_Encoded) يحتوي على الأرقام.
- في هذا الكود، قمنا بتحويل عمود Favorite_Color من قيم نصية (red, green, blue) إلى أرقام باستخدام LabelEncoder.
- fit_transform: يحول القيم النصية إلى أرقام مميزة لكل فئة.
- red = 2
- green = 1
- blue = 0
النتيجة:
DataFrame يحتوي على العمود الأصلي مع عمود جديد (Favorite_Color_Encoded) يحتوي على الأرقام.
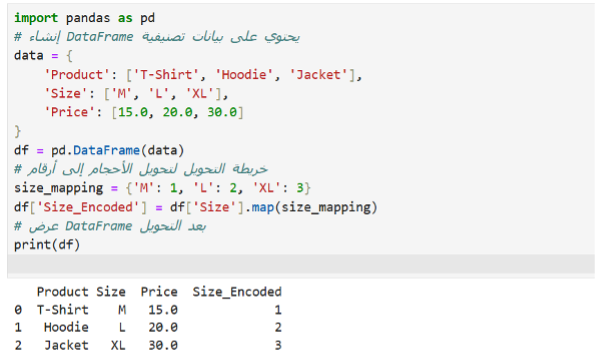
Ordinal Encoding:
في هذا الكود، قمنا بتحويل عمود Size من قيم نصية (M, L, XL) إلى أرقام باستخدام خريطة تحويل (size_mapping):
- map(size_mapping): تستبدل القيم النصية في عمود Size بالأرقام:
M = 1
L = 2
XL = 3
النتيجة:
DataFrame يحتوي على عمود جديد (Size_Encoded) مع القيم المرمزة. ✔️
في هذا الكود، قمنا بتحويل عمود Size من قيم نصية (M, L, XL) إلى أرقام باستخدام خريطة تحويل (size_mapping):
- map(size_mapping): تستبدل القيم النصية في عمود Size بالأرقام:
M = 1
L = 2
XL = 3
النتيجة:
DataFrame يحتوي على عمود جديد (Size_Encoded) مع القيم المرمزة. ✔️
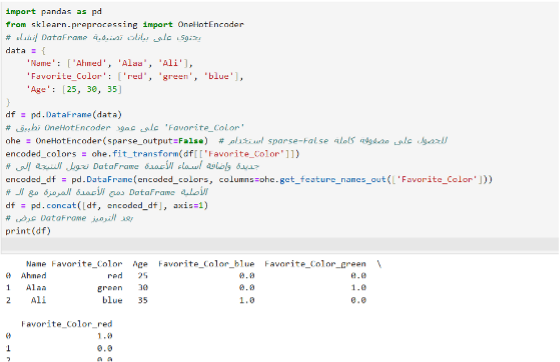
One-Hot Encoding:
في هذا الكود، حولنا عمود Favorite_Color من قيم نصية إلى أعمدة منفصلة باستخدام OneHotEncoder:
- fit_transform: يحول القيم النصية إلى مصفوفة تحتوي على 0 و1.
- get_feature_names_out: يسمي الأعمدة الناتجة بناءً على القيم الأصلية.
- concat: دمج الأعمدة المرمزة مع البيانات الأصلية.
النتيجة:
DataFrame يحتوي على أعمدة جديدة لكل لون مع ترميز مناسب (0/1). ✔️
في هذا الكود، حولنا عمود Favorite_Color من قيم نصية إلى أعمدة منفصلة باستخدام OneHotEncoder:
- fit_transform: يحول القيم النصية إلى مصفوفة تحتوي على 0 و1.
- get_feature_names_out: يسمي الأعمدة الناتجة بناءً على القيم الأصلية.
- concat: دمج الأعمدة المرمزة مع البيانات الأصلية.
النتيجة:
DataFrame يحتوي على أعمدة جديدة لكل لون مع ترميز مناسب (0/1). ✔️
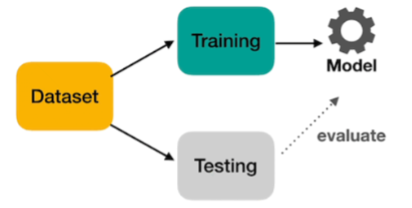
خلونا نتكلم عن تقسيم البيانات في تعلم الآلة: لو تبغى نموذجك يتعلم بشكل صحيح ويعطيك أداء حقيقي، لازم تقسم بياناتك صح. ليش؟ وكيف تختار النسبة؟ ومتى تحتاج طرق متقدمة؟ خلونا نشرح كل شيء ببساطة . x.com
أول شيء، ليش نحتاج تقسيم البيانات؟
- إذا ما قسمت البيانات، تقييم نتائج النموذج تكون غير واضحة.
- لما تختبر النموذج بنفس البيانات اللي دربته عليها، النموذج يحفظها بدل ما يتعلم الأنماط.
النتيجة ؟
- النموذج اكيد بيعطي أداء عالي في معايير التقييم، لكن بالغالب ما يتعامل كويس مع بيانات جديدة اللا اذا حالفك الحظ😁.
- بكذا، نتائج التقييم ما تعني شي لأن النموذج يعتبر حافظ البيانات و ما نقدر نجزم انه قادر يعمم على بيانات ما شافها.
الحل؟
قسم البيانات إلى:
- تدريب : (Training) يعّلم النموذج.
- اختبار: (Testing) نستخدمه عشان نشوف أداء النموذج على بيانات جديدة.
- هالطريقة تقلل من المشكلة وتضمن نموذج يعمم بشكل جيد.
- إذا ما قسمت البيانات، تقييم نتائج النموذج تكون غير واضحة.
- لما تختبر النموذج بنفس البيانات اللي دربته عليها، النموذج يحفظها بدل ما يتعلم الأنماط.
النتيجة ؟
- النموذج اكيد بيعطي أداء عالي في معايير التقييم، لكن بالغالب ما يتعامل كويس مع بيانات جديدة اللا اذا حالفك الحظ😁.
- بكذا، نتائج التقييم ما تعني شي لأن النموذج يعتبر حافظ البيانات و ما نقدر نجزم انه قادر يعمم على بيانات ما شافها.
الحل؟
قسم البيانات إلى:
- تدريب : (Training) يعّلم النموذج.
- اختبار: (Testing) نستخدمه عشان نشوف أداء النموذج على بيانات جديدة.
- هالطريقة تقلل من المشكلة وتضمن نموذج يعمم بشكل جيد.
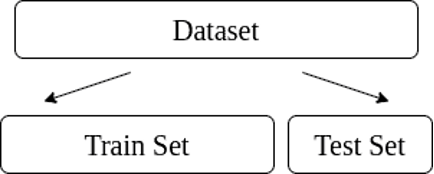
كيف تختار النسبة المناسبة لتقسيم البيانات في تعلم الآلة؟ 🤔
اختيار النسبة يعتمد على طبيعة بياناتك:
- إذا كانت بياناتك كبيرة، نسبة مثل 80:20 أو 70:30 تكون خيار جيد.
- إذا كانت البيانات صغيرة، التقسيم الثابت ممكن ما يكون كافي لتقييم النموذج بشكل دقيق.
لكن التقسيم الثابت مو دائمًا الأفضل سواءً للبيانات الكبيرة او الصغيرة، لأنه قد يفوتك اختبار النموذج على أجزاء مهمة من البيانات.
هنا تجي فائدة Cross Validation.
يوفر طريقة أدق بتقسيم البيانات لأجزاء متعددة (Folds) واختبار النموذج على كل جزء.
ما راح أشرح Cross Validation في هذا الثريد لكن بشرحها بالتفصيل قريبًا🤝🌹
اختيار النسبة يعتمد على طبيعة بياناتك:
- إذا كانت بياناتك كبيرة، نسبة مثل 80:20 أو 70:30 تكون خيار جيد.
- إذا كانت البيانات صغيرة، التقسيم الثابت ممكن ما يكون كافي لتقييم النموذج بشكل دقيق.
لكن التقسيم الثابت مو دائمًا الأفضل سواءً للبيانات الكبيرة او الصغيرة، لأنه قد يفوتك اختبار النموذج على أجزاء مهمة من البيانات.
هنا تجي فائدة Cross Validation.
يوفر طريقة أدق بتقسيم البيانات لأجزاء متعددة (Folds) واختبار النموذج على كل جزء.
ما راح أشرح Cross Validation في هذا الثريد لكن بشرحها بالتفصيل قريبًا🤝🌹
خلونا نشوف كيف نقدر نقسم بياناتنا للتدريب والاختبار في الكود:
الشرح:
test_size=0.3: يخصص 30٪ للاختبار و70٪ للتدريب.
random_state=42: يثبت تقسيم البيانات كل مرة تشغل الكود، عشان تكون النتائج ثابتة وتقدر تقارن الأداء بسهولة.
X: تمثل الميزات (Features) أو البيانات المدخلة التي يعتمد عليها النموذج.
y: تمثل القيم المستهدفة (Targets) التي يحاول النموذج التنبؤ بها.
X_train, y_train: تستخدم لتدريب النموذج.
X_test, y_test: لاختبار أداء النموذج.
بهذا التقسيم، بياناتك بتكون جاهزة ومتوازنة لتعلم الآلة! 🫡✔
الشرح:
test_size=0.3: يخصص 30٪ للاختبار و70٪ للتدريب.
random_state=42: يثبت تقسيم البيانات كل مرة تشغل الكود، عشان تكون النتائج ثابتة وتقدر تقارن الأداء بسهولة.
X: تمثل الميزات (Features) أو البيانات المدخلة التي يعتمد عليها النموذج.
y: تمثل القيم المستهدفة (Targets) التي يحاول النموذج التنبؤ بها.
X_train, y_train: تستخدم لتدريب النموذج.
X_test, y_test: لاختبار أداء النموذج.
بهذا التقسيم، بياناتك بتكون جاهزة ومتوازنة لتعلم الآلة! 🫡✔

تجهيز البيانات في تعلم الآلة هو الأساس لأي نموذج ناجح. 🔥🫡
نظفّنا البيانات المفقودة بالحذف أو الإكمال، ثم حولنا النصوص لأرقام باستخدام تقنيات Encoding المناسبة، وقسمنا البيانات للتدريب والاختبار لضمان تقييم عادل. لكن كيف نحدد الميزات المؤثرة فعلاً؟ وهل تقنيات مثل L1 و L2 Regularization هي الحل؟ الإجابة في الثريد القادم، ترقبوا...
نظفّنا البيانات المفقودة بالحذف أو الإكمال، ثم حولنا النصوص لأرقام باستخدام تقنيات Encoding المناسبة، وقسمنا البيانات للتدريب والاختبار لضمان تقييم عادل. لكن كيف نحدد الميزات المؤثرة فعلاً؟ وهل تقنيات مثل L1 و L2 Regularization هي الحل؟ الإجابة في الثريد القادم، ترقبوا...
جاري تحميل الاقتراحات...