

🔥من أين اكتسب GPT-4o سرعته ودقته؟
أحد مصادر القوة التي اعتمد عليها GPT-4o هي قدرته على قراءة النصوص ومعالجتها من خلال تقسيمها tokenization.
▫️تخيل تقرأ جملة، وأنت تقطعها إلى كلمات أو أجزاء صغيرة لتفهمها. هذا بالضبط ما يفعله النموذج، ولكنه يستخدم وحدات تسمى (توكينات) (tokens)
أحد مصادر القوة التي اعتمد عليها GPT-4o هي قدرته على قراءة النصوص ومعالجتها من خلال تقسيمها tokenization.
▫️تخيل تقرأ جملة، وأنت تقطعها إلى كلمات أو أجزاء صغيرة لتفهمها. هذا بالضبط ما يفعله النموذج، ولكنه يستخدم وحدات تسمى (توكينات) (tokens)

ماذا حدث؟
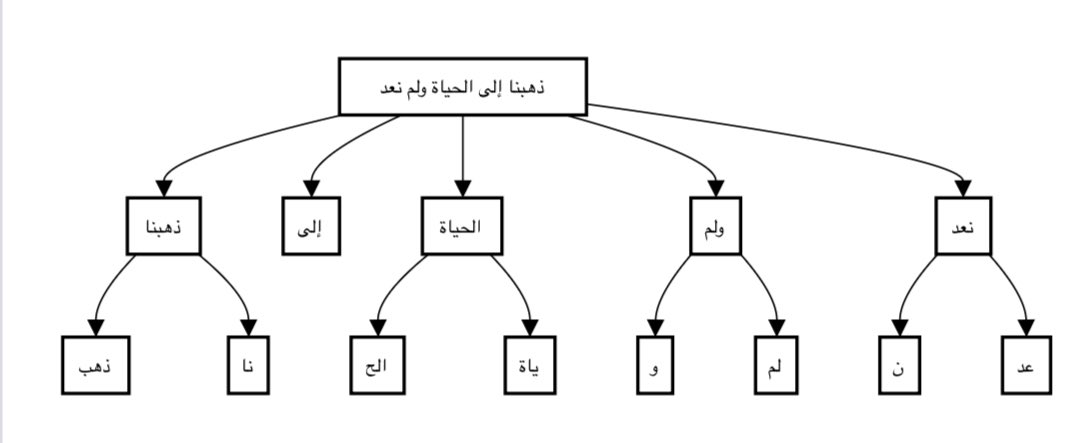
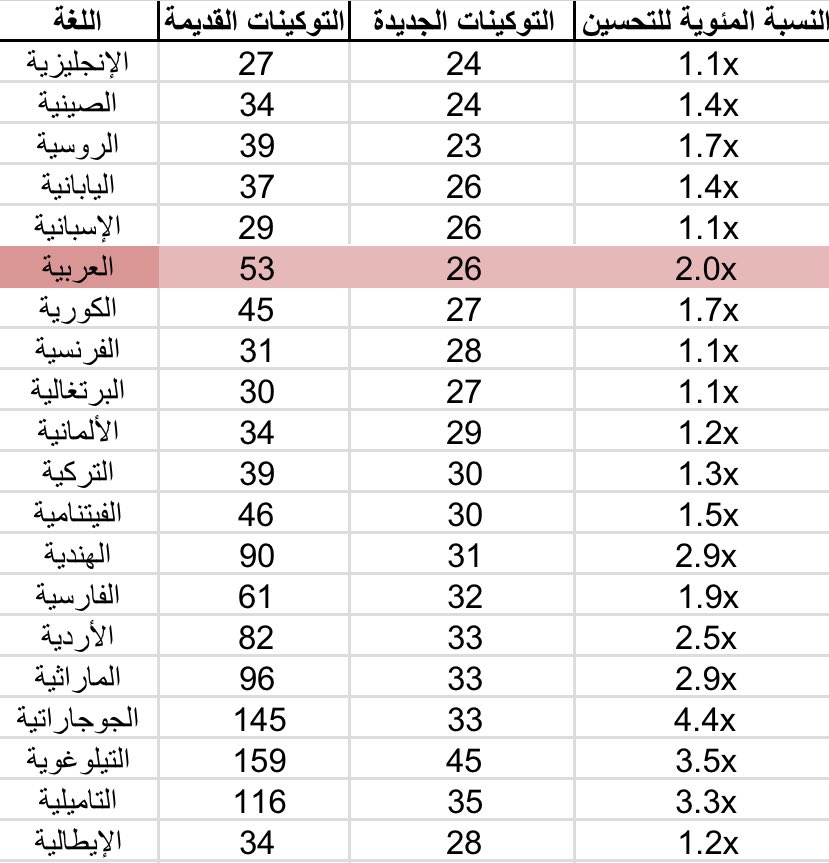
GPT-4 كان عدد التوكينات بالنسبة للغة العربية هو (53) أي أنه يعمل على تقسيم الجملة إلى كلمات / وحروف / عدد التوكينات يصل إلى 53 وهذا يرهق النموذج ويوقعه في أخطاء.
مثال:
لو كان لدينا جملة "ذهبنا إلى الحياة ولم نعد" فإن GPT-4 يقسمها كما بالصورة👇🏻(مثال للتقسم)
GPT-4 كان عدد التوكينات بالنسبة للغة العربية هو (53) أي أنه يعمل على تقسيم الجملة إلى كلمات / وحروف / عدد التوكينات يصل إلى 53 وهذا يرهق النموذج ويوقعه في أخطاء.
مثال:
لو كان لدينا جملة "ذهبنا إلى الحياة ولم نعد" فإن GPT-4 يقسمها كما بالصورة👇🏻(مثال للتقسم)

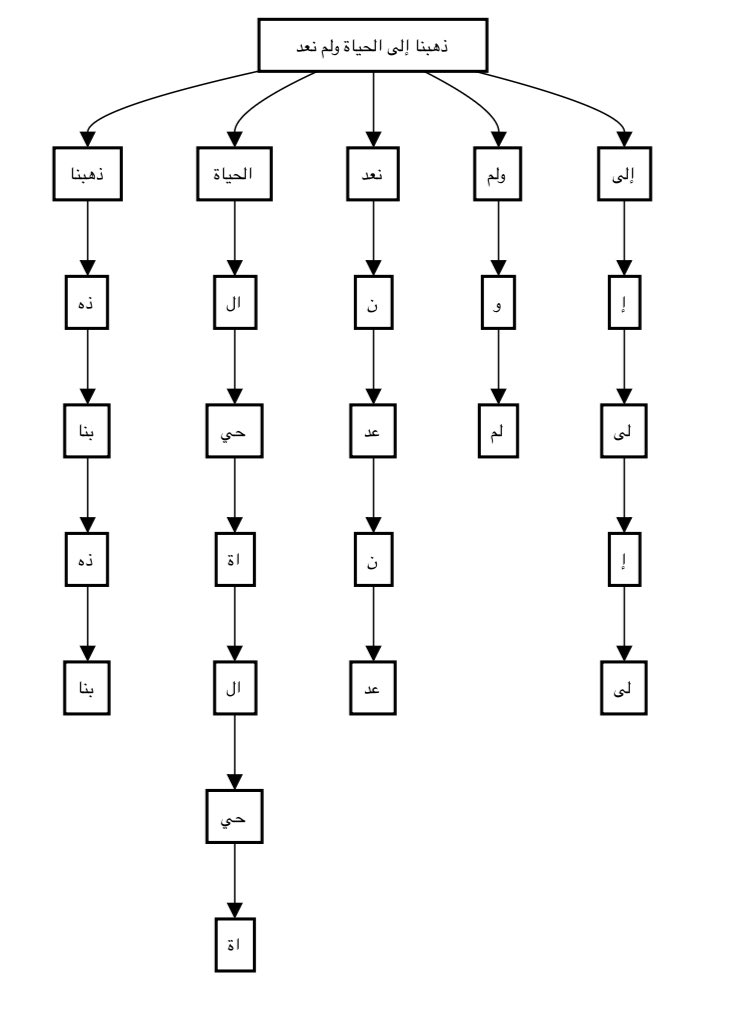
أما الجديد GPT-4o فهو يقسمها إلى عدد أقل من التوكينات (26) فقط وهذا يعني بأنه يحتفظ بالكلمات ككتلة واحدة قدر الإمكان مما يقلل العدد الإجمالي للتوكينات.
مثال
لنفس الجملة السابقة نلاحظ أن GPT-4o يقسمها لعدد أقل👇🏻(مثال للتقسيم)
مثال
لنفس الجملة السابقة نلاحظ أن GPT-4o يقسمها لعدد أقل👇🏻(مثال للتقسيم)
باختصار
(ذهبنا إلى الحياة ولم نعد)
▫️GPT-4
يحتاج إلى تقسيم الجملة إلى 53 توكين، أي كل جزء صغير من الجملة (مثل “ذه” و”بنا” و”إلى”) يتم معالجته كوحدة مستقلة
▪️GPT-4o
يحتاج إلى تقسيم الجملة إلى 26 توكين فقط، أي كل جزء أكبر (مثل “ذهبنا” و”إلى” و”الحياة”) يتم معالجته كوحدة واحدة
(ذهبنا إلى الحياة ولم نعد)
▫️GPT-4
يحتاج إلى تقسيم الجملة إلى 53 توكين، أي كل جزء صغير من الجملة (مثل “ذه” و”بنا” و”إلى”) يتم معالجته كوحدة مستقلة
▪️GPT-4o
يحتاج إلى تقسيم الجملة إلى 26 توكين فقط، أي كل جزء أكبر (مثل “ذهبنا” و”إلى” و”الحياة”) يتم معالجته كوحدة واحدة
ماذا يعني ذلك؟
عندما تصبح عدد التوكينات أقل في النموذج، فإنه:
= يعالج النصوص بسرعة أكبر لأنه يتعامل مع عدد أقل من الأجزاء
=البيانات التي يحتاج لمعالجتها تصبح أقل، أي يقل استهلاك الموارد
=يفهم النص بشكل أفضل لأنه يتعامل مع أجزاء أكبر تحمل معنى أكثر
عندما تصبح عدد التوكينات أقل في النموذج، فإنه:
= يعالج النصوص بسرعة أكبر لأنه يتعامل مع عدد أقل من الأجزاء
=البيانات التي يحتاج لمعالجتها تصبح أقل، أي يقل استهلاك الموارد
=يفهم النص بشكل أفضل لأنه يتعامل مع أجزاء أكبر تحمل معنى أكثر
مقارنة التحسينات في هذا المجال بين GPT-4 و GPT-4o
جاري تحميل الاقتراحات...