

🧵《纽约时报》刚刚起诉 OpenAI 侵犯版权,因为它们使用其内容训练 ChatGPT。
这是迄今为止指控gen AI侵犯版权的最好案例
有些指控令人震惊!以下是最 🔥 部分:
这是迄今为止指控gen AI侵犯版权的最好案例
有些指控令人震惊!以下是最 🔥 部分:

1/
首先,诉状明确提出了版权侵权的主张,强调了《纽约时报》的文章与 ChatGPT 的输出之间的 "访问和实质性相似性"。
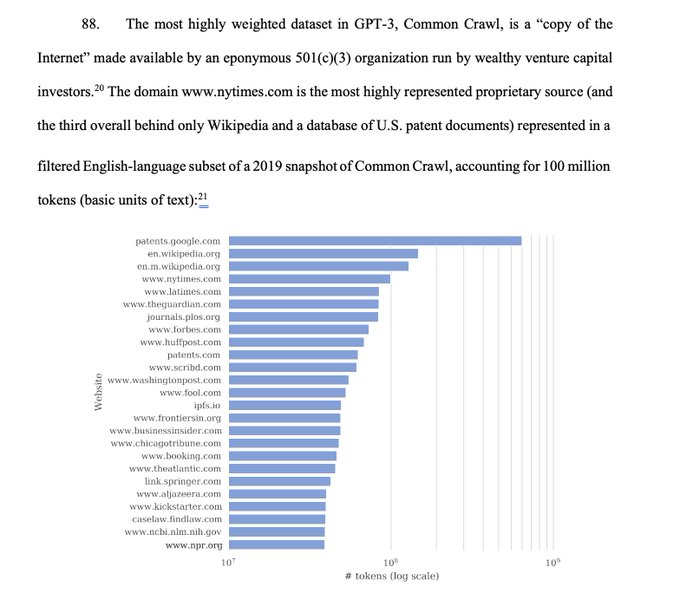
关键事实:《纽约时报》是用于训练 GPT 的 Common Crawl 中最大的一个专有数据集。
首先,诉状明确提出了版权侵权的主张,强调了《纽约时报》的文章与 ChatGPT 的输出之间的 "访问和实质性相似性"。
关键事实:《纽约时报》是用于训练 GPT 的 Common Crawl 中最大的一个专有数据集。
2/
NYT指控 OpenAI/微软非法使用了其数百万篇文章。
不仅如此,他们还在模型中给予纽约时报的内容额外的 "权重",因为这些内容非常有价值。
NYT指控 OpenAI/微软非法使用了其数百万篇文章。
不仅如此,他们还在模型中给予纽约时报的内容额外的 "权重",因为这些内容非常有价值。

3/
而且,还有一些确凿的证据,证明《纽约时报》的内容是逐字复制的。
投诉中抄袭的直观证据十分明显。复制的文字为红色,新的 GPT 文字为黑色--参见此处的证据 。
而且,还有一些确凿的证据,证明《纽约时报》的内容是逐字复制的。
投诉中抄袭的直观证据十分明显。复制的文字为红色,新的 GPT 文字为黑色--参见此处的证据 。

4/
该诉讼称,微软和 ChatGPT 可以从《纽约时报》文章中生成逐字摘录,这导致用户无需前往 NYT.com 并付款。
由于ChatGPT 与“NYT培训的LLM”合作, $MSFT 股票的市值增加了数万亿美元。
该诉讼称,微软和 ChatGPT 可以从《纽约时报》文章中生成逐字摘录,这导致用户无需前往 NYT.com 并付款。
由于ChatGPT 与“NYT培训的LLM”合作, $MSFT 股票的市值增加了数万亿美元。



5/
《纽约时报》创造的不仅仅是一篇文章,它还涉及原创性和创作过程。投诉将 @OpenAI描述为以利润为导向且封闭。它将这与新闻业的公共利益形成鲜明对比。
OpenAI 认为,他们使用《纽约时报》的内容构成了 "合理使用",因为这是 "变革性的"。
NYT辩称,这并不具有任何改变性,而 ChatGPT 只是直接访问《纽约时报》的替代品。
《纽约时报》创造的不仅仅是一篇文章,它还涉及原创性和创作过程。投诉将 @OpenAI描述为以利润为导向且封闭。它将这与新闻业的公共利益形成鲜明对比。
OpenAI 认为,他们使用《纽约时报》的内容构成了 "合理使用",因为这是 "变革性的"。
NYT辩称,这并不具有任何改变性,而 ChatGPT 只是直接访问《纽约时报》的替代品。




@OpenAI 7/
最后,当 ChatGPT 不是转载《纽约时报》的内容时,它就是在编造内容(幻觉),并将其错误地归于《纽约时报》。
该指控将人们害怕的东西--幻觉--扯了进来,并以此立案,列举了《纽约时报》文章内容被编造的例子。
最后,当 ChatGPT 不是转载《纽约时报》的内容时,它就是在编造内容(幻觉),并将其错误地归于《纽约时报》。
该指控将人们害怕的东西--幻觉--扯了进来,并以此立案,列举了《纽约时报》文章内容被编造的例子。


@OpenAI 该案可能是AI和版权的分水岭,原作者@CeciliaZin @MatthewBerman
关注我 @FinanceYF5 了解有关AI的更多信息。
如果您发现这有用,请在下面给我点赞/转发以支持 👇
关注我 @FinanceYF5 了解有关AI的更多信息。
如果您发现这有用,请在下面给我点赞/转发以支持 👇
جاري تحميل الاقتراحات...