

⚡ Destripando el ALGORITMO de X (Twitter)
X publicó parte de su código fuente hace meses pero poca gente lo ha estudiado a fondo.
Yo he leído todo lo que se ha publicado y estudiado el source para que tú no tengas que hacerlo.
En este hilo os cuento TODOS sus entresijos 🧵👇
X publicó parte de su código fuente hace meses pero poca gente lo ha estudiado a fondo.
Yo he leído todo lo que se ha publicado y estudiado el source para que tú no tengas que hacerlo.
En este hilo os cuento TODOS sus entresijos 🧵👇
- ¿Por qué viralizan unos posts y otros no?
- ¿Tiene cada cuenta una puntuación de scoring/karma?
- ¿Qué hace subir o bajar dicho karma?
- ¿Cuántas de mis publicaciones al día pueden funcionar?
- ¿La tortilla de patatas con cebolla o sin cebolla?
- ¿Tiene cada cuenta una puntuación de scoring/karma?
- ¿Qué hace subir o bajar dicho karma?
- ¿Cuántas de mis publicaciones al día pueden funcionar?
- ¿La tortilla de patatas con cebolla o sin cebolla?
Eso es lo que sabrás una vez completes este hilo. ¡Ahí es na! Voy directo a otro shadow ban pero estoy on fire y me la pela.
Respondo a una de las preguntas antes de nada: ¡sin cebolla siempre!
Respondo a una de las preguntas antes de nada: ¡sin cebolla siempre!

Coñas aparte, me conocéis: hablaré en todo momento de cosas VERIFICABLES empíricamente:
1/ Estén públicas en el código fuente que liberaron.
2/ Hayan sido reconocidas oficialmente por X o Elon Musk.
2/ Tests reproducibles e inequívocos cuando alguien sufre un shadow ban.
1/ Estén públicas en el código fuente que liberaron.
2/ Hayan sido reconocidas oficialmente por X o Elon Musk.
2/ Tests reproducibles e inequívocos cuando alguien sufre un shadow ban.
Como sé que la atención lectora hoy día está bajo mínimos, os lo voy a dar en cómodas "perlas" numeradas. Ya lo masco yo por vosotros.
¡Vamos al lío!
¡Vamos al lío!
1. X (Twitter) gana dinero mostrándote anuncios. Cuantos más anuncios veas, más dinero ganan. El objetivo del algoritmo es por tanto, como es lógico, mostrarte contenido que te haga pasar en X el mayor tiempo posible.
¡De cajón, vamos!
¡De cajón, vamos!
¡Ojo! No necesariamente el contenido que más te guste. ¡Sino con el que más tiempo pases! Este es un detalle sutil pero de suma importancia.

¿Te has preguntado alguna vez por qué aparecen a veces temas conflictivos, de política, etc. en tu TL que no te gustan en absoluto?
Bueno, porque seas consciente o no de ello, REACCIONASTE a temas parecidos en el pasado que resultaron en MÁS TIEMPO en la app.
Psicología pura.
Bueno, porque seas consciente o no de ello, REACCIONASTE a temas parecidos en el pasado que resultaron en MÁS TIEMPO en la app.
Psicología pura.
2. Para conseguir esto, X intenta adivinar de ti (estudiando tu comportamiento) lo siguiente:
- ¿Con qué tipo de contenido es más probable que interactúes?
- ¿Qué está en tendencia entre los usuarios que tienen gustos similares a los tuyos?
- ¿Con qué tipo de contenido es más probable que interactúes?
- ¿Qué está en tendencia entre los usuarios que tienen gustos similares a los tuyos?

3. X responde a esas preguntas y construye tu TL (tus contenidos) así:
A. Selecciona 1500 tweets que piensa que te gustarán más entre los 100 millones de tweets diarios.
B. Asigna a cada tweet un scoring de "probabilidad de interacción" y los ordenas de mayor a menor.
A. Selecciona 1500 tweets que piensa que te gustarán más entre los 100 millones de tweets diarios.
B. Asigna a cada tweet un scoring de "probabilidad de interacción" y los ordenas de mayor a menor.
C. Limpia de la lista de tweets filtrando aquellos que considera malos, de cuentas bloqueadas, shadow baneadas, etc. Y entre los tweets finales, inserta algunos que son anuncios.
Comprender cómo X selecciona, clasifica y filtra los posts puede ayudarte a viralizar.
Comprender cómo X selecciona, clasifica y filtra los posts puede ayudarte a viralizar.
Ahora hablaré en profundidad de cada punto. Que resumiendo son:
A. Obtención de candidatos (Elegir lots tweets para ti).
B. Sistema de ranking.
C. Heurísticas y filtrado.
A. Obtención de candidatos (Elegir lots tweets para ti).
B. Sistema de ranking.
C. Heurísticas y filtrado.
A. Para la obtención de tweets candidatos, X utiliza:
- El grafo de seguidores que visualiza quién te sigue.
- Datos como me gusta, reposts, bookmarks, y respuestas.
- Datos de usuario como "silenciar", dejar de seguir y reportes de spam.
- El grafo de seguidores que visualiza quién te sigue.
- Datos como me gusta, reposts, bookmarks, y respuestas.
- Datos de usuario como "silenciar", dejar de seguir y reportes de spam.
X selecciona 1500 tweets de un conjunto de más de 100M a través de diferentes fuentes:
→ Cuentas a las que sigues
- Aproximadamente el 50% vienen de ahí. ¿Recuerdas los días en los que sólo te aparecían tweets de las personas que seguías? Eso se acabó con esto.
→ Cuentas a las que sigues
- Aproximadamente el 50% vienen de ahí. ¿Recuerdas los días en los que sólo te aparecían tweets de las personas que seguías? Eso se acabó con esto.
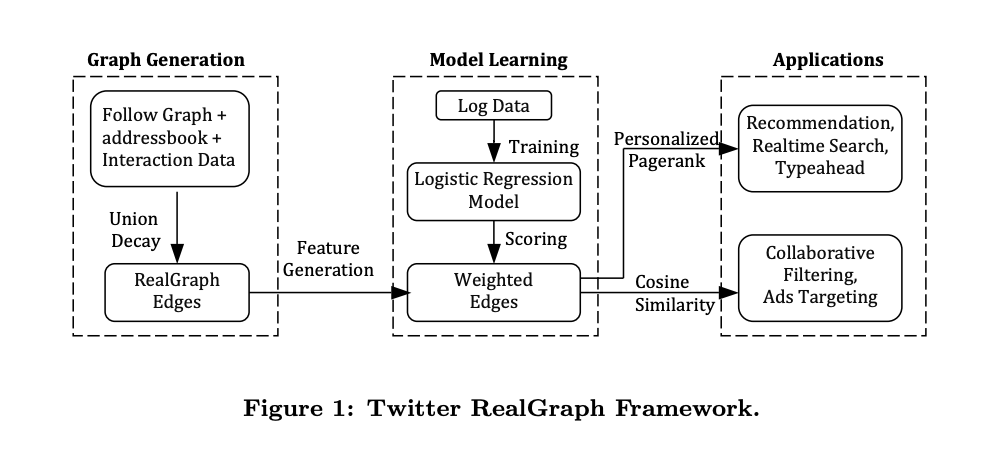
- ¡No te muestra todos, claro! En este paso se utiliza un modelo de regresión logística compleja para filtrar tweets irrelevantes y seleccionar cuidadosamente los mensajes que considera más importantes de los usuarios a los que sigues.
- Esto se consigue mediante algo que llaman "RealGraph". Este grafo predice la probabilidad de que dos usuarios interactúen. Cuanto mayor sea la puntuación, es más probable que se muestren en tu feed.
- Los mejores tweets, pasan a la siguiente fase.
- Los mejores tweets, pasan a la siguiente fase.
→ Cuentas que no sigues (el otro 50%)
¿Y si no lo sigues, cómo deciden qué mostrarte? A través de dos formas combinadas:
1/ Tu grafo social:
- ¿Con qué posts interactúan las personas a las que sigo?
- ¿Quiénes dan like a posts similares a los tuyos y qué les ha gustado?
¿Y si no lo sigues, cómo deciden qué mostrarte? A través de dos formas combinadas:
1/ Tu grafo social:
- ¿Con qué posts interactúan las personas a las que sigo?
- ¿Quiénes dan like a posts similares a los tuyos y qué les ha gustado?
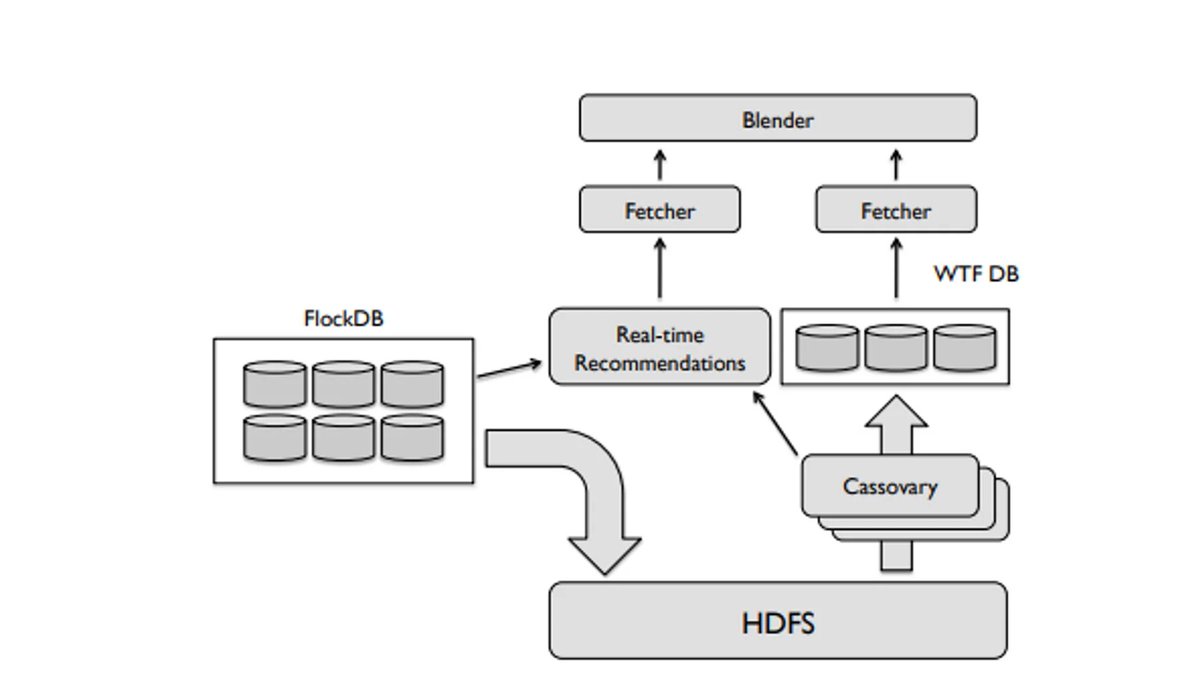
2/ "Embedding spaces" (clusters o grupos de clasificación).
Que básicamente responden a la pregunta: ¿qué tweets y usuarios son SIMILARES a tus intereses?
Básicamente, el algoritmo utiliza tu contenido para agruparte con otros usuarios similares en clusters.
Que básicamente responden a la pregunta: ¿qué tweets y usuarios son SIMILARES a tus intereses?
Básicamente, el algoritmo utiliza tu contenido para agruparte con otros usuarios similares en clusters.
Y esto es MUY INTERESANTE. Existen 145k comunidades que se actualizan cada 3 semanas. Los usuarios y los posts se representan pueden pertenecer a múltiples comunidades.
Y no tienes forma (que yo sepa) de saber en cuáles de ellas te han clasificado.
Y no tienes forma (que yo sepa) de saber en cuáles de ellas te han clasificado.
Estas "comunidades ocultas" o clusters varían en tamaño, desde algunos miles de usuarios para grupos de colegas hasta cientos de millones de usuarios para noticias o temas de cultura popular.
Y esto me pone calentísimo porque sabiendo de su existencia se entiende por qué:
1/ Cuando uno de tus tweets viraliza dentro de una de estas comunidades, pronto todos lo consumen. Por eso cuando digo algo que toca a los "AI Haters" se lía bárbara porque todo ese cluster lo ve.
1/ Cuando uno de tus tweets viraliza dentro de una de estas comunidades, pronto todos lo consumen. Por eso cuando digo algo que toca a los "AI Haters" se lía bárbara porque todo ese cluster lo ve.
2/ Crear un tipo de contenido vertical hace que tu cuenta crezca más rápidamente. Esto es algo que siempre hemos sabido los creadores de contenido en Twitter pero tras conocer los clusters, tiene todo el sentido del mundo. ¡Si te posicionas en un cluster, te haces oír!
¡De hecho es que publicar cosas FUERA de tu cluster penaliza!

¿Y cómo rankea X para poder seleccionar 1500 de entre todo lo anterior (cuentas que te sigue + que no te siguen)?
En teoría, hace unos meses X utilizaba múltiples variables que podíamos utilizar para maximizar nuestro alcance. Y podían tanto sumar, como restar:
En teoría, hace unos meses X utilizaba múltiples variables que podíamos utilizar para maximizar nuestro alcance. Y podían tanto sumar, como restar:
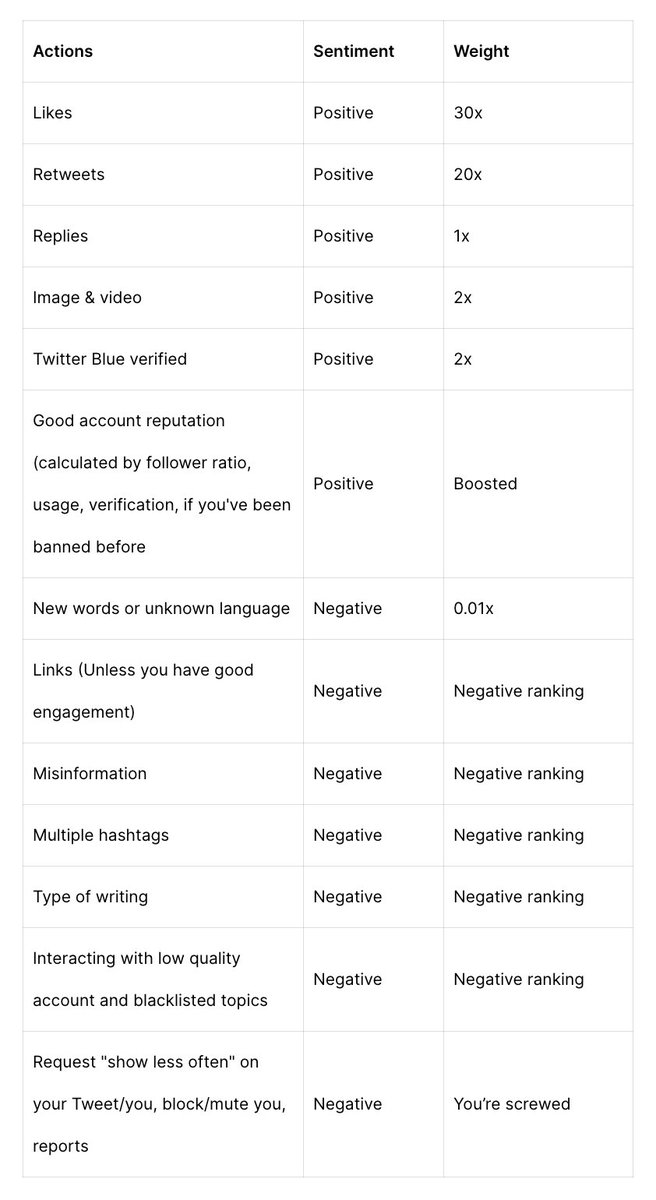
La fuente que he consultado es de antes de que introdujeran los "bookmarks" así que no sé qué peso tienen. Pero si miráis en la imagen igual os sorprenderá ver que los LIKEs suman 30 puntos mientras que los reposts suman 20. Es decir, ¡los LIKES consiguen más alcance potencial!
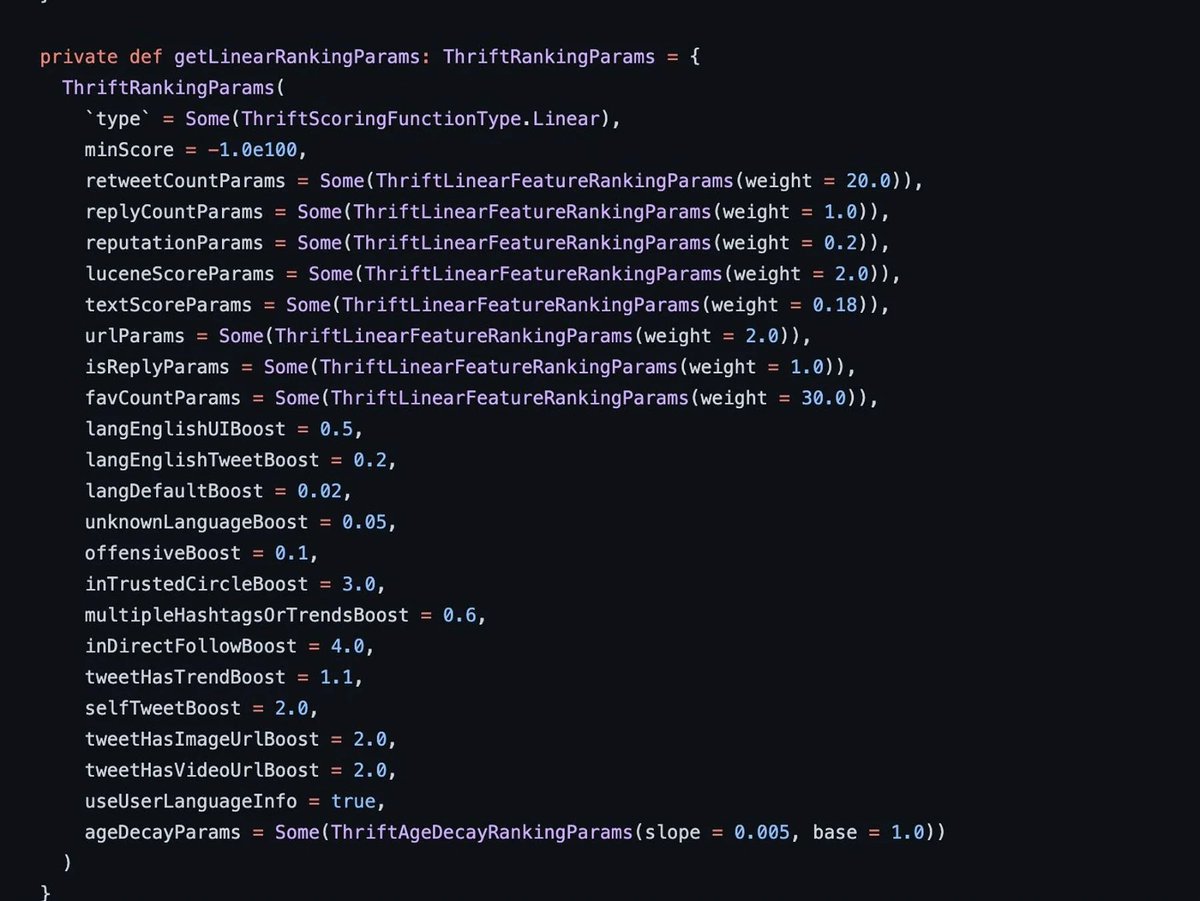
¡Pero OJO! He estado buscando dichos parámetros en el código fuente actual y parece ser que esta parte ha sido sustituida por... ¡oh, sorpresa! Un sistema puro de IA a través de TensorFlow.
Si alguien puede aportar algo de luz sobre esta parte se lo agradezco.
Si alguien puede aportar algo de luz sobre esta parte se lo agradezco.
B. Sistema de ránking.
Bien, ya tenemos 1500 tweets listos. ¡Ahora hay que ordenarlos y presentarlos en tu TL!
¿Cómo? Pues a través de una puntuación que van recibiendo los tweets que mide la probabilidad de que vayas a interactuar (pasar más tiempo) con dicho tweet.
Bien, ya tenemos 1500 tweets listos. ¡Ahora hay que ordenarlos y presentarlos en tu TL!
¿Cómo? Pues a través de una puntuación que van recibiendo los tweets que mide la probabilidad de que vayas a interactuar (pasar más tiempo) con dicho tweet.
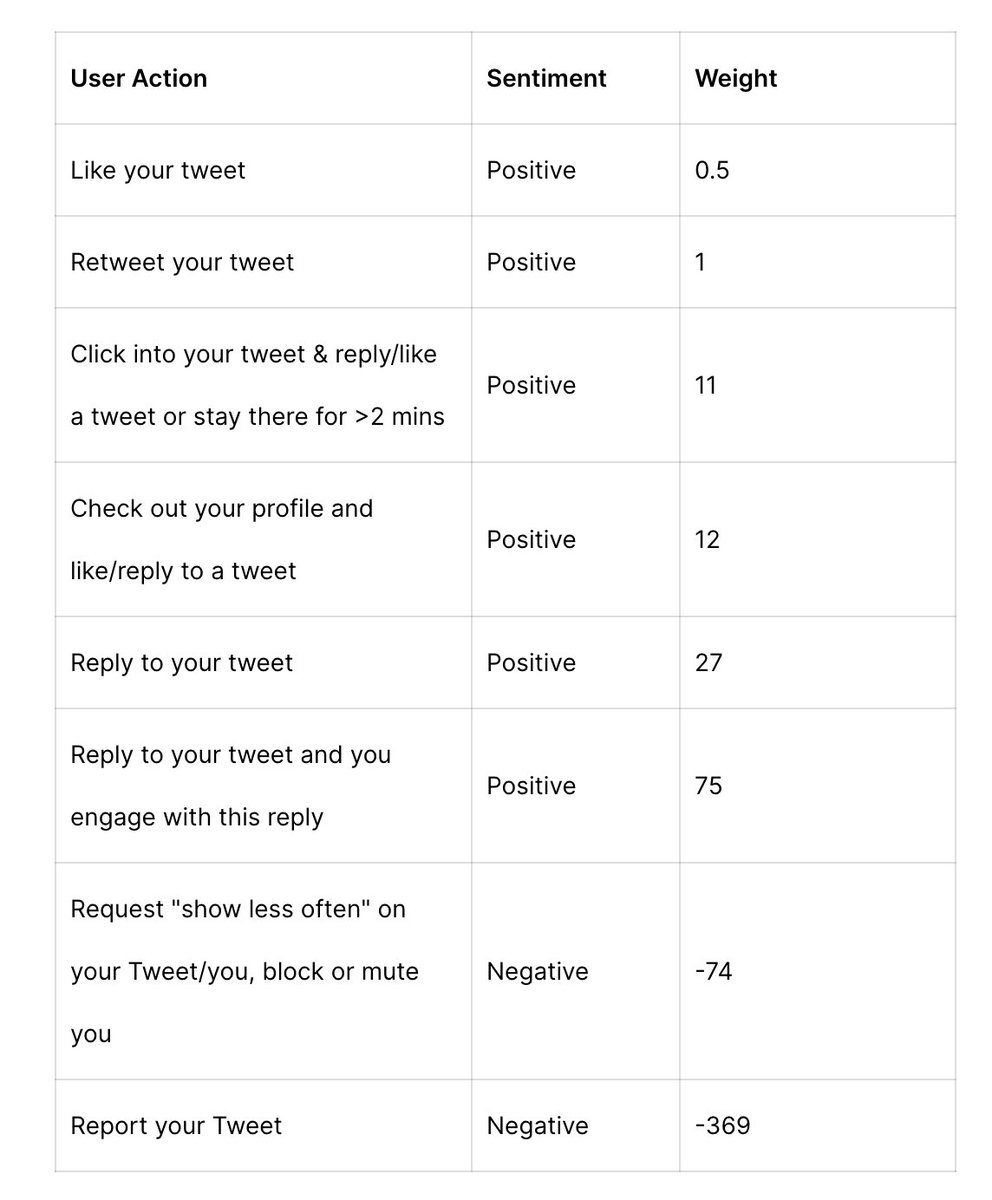
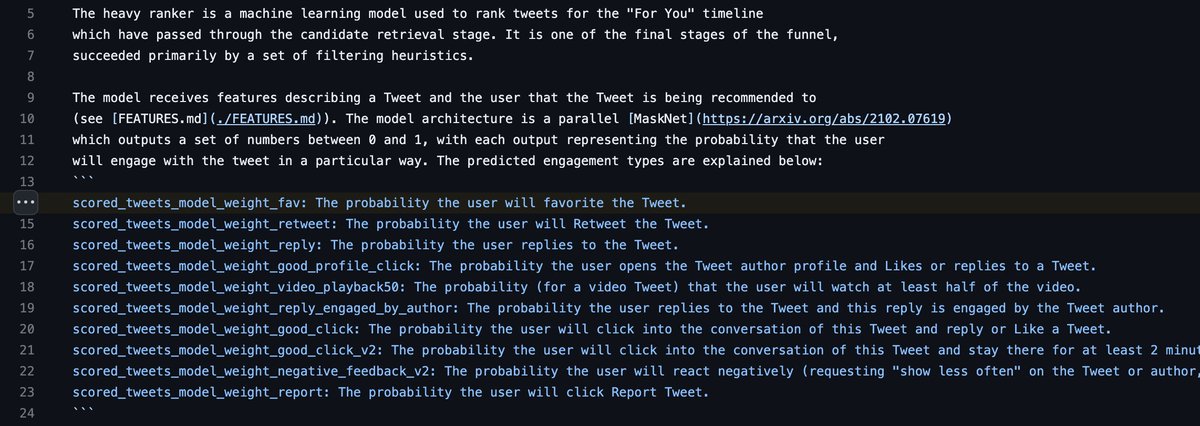
Explicación con ejemplos comprensibles:

C. Heurísticas y filtrado.
Después de esta clasificación, se utilizan heurísticas y filtros para que tu TL sea lo más diverso posible.
💡 ¿Conocías el truco de editar el tweet para que volviera a subir posiciones?
Después de esta clasificación, se utilizan heurísticas y filtros para que tu TL sea lo más diverso posible.
💡 ¿Conocías el truco de editar el tweet para que volviera a subir posiciones?

BONUS. Cosas que deberías saber.
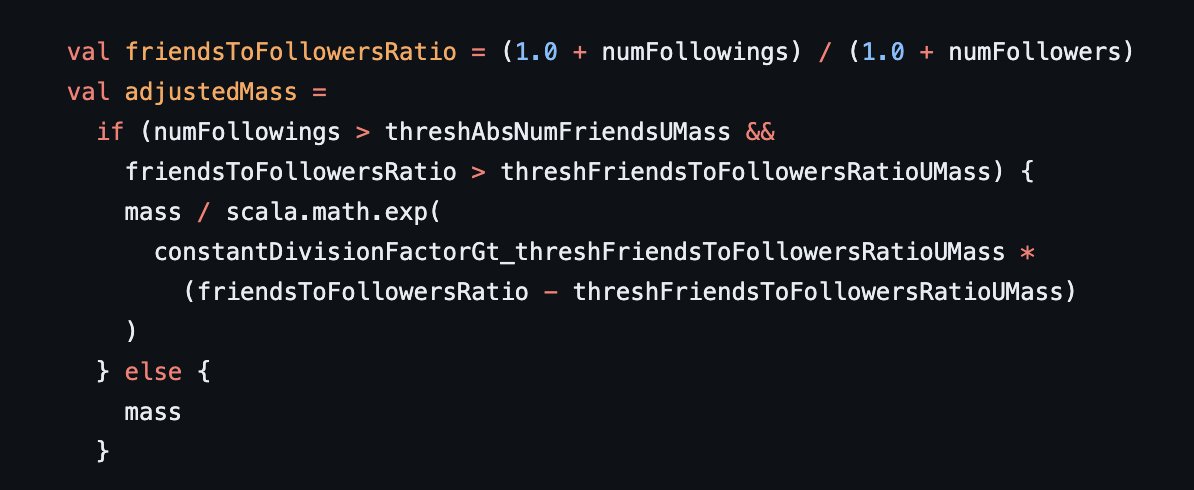
1/ Tu alcance de cuenta se ve afectado negativamente si tu ratio de seguidores es malo (si sigues a más del 60% de tus seguidores).
1/ Tu alcance de cuenta se ve afectado negativamente si tu ratio de seguidores es malo (si sigues a más del 60% de tus seguidores).
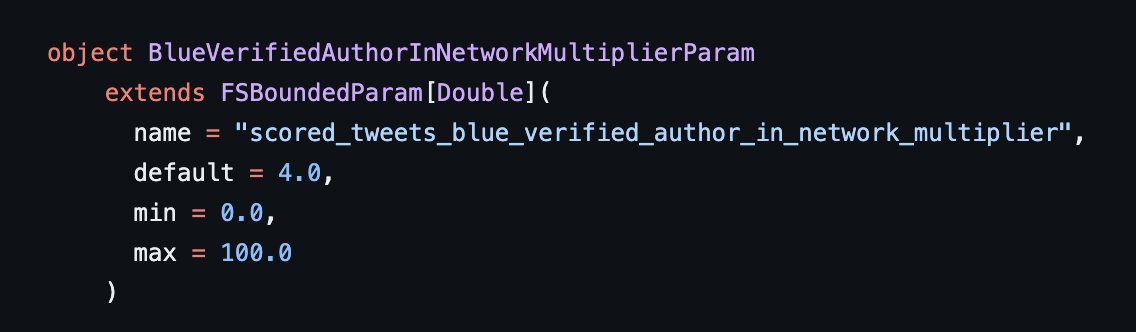
2/ Tener el check azul de verificado tiene un boost positivo (como ya habían reconocido desde X y como quería Elon Musk).
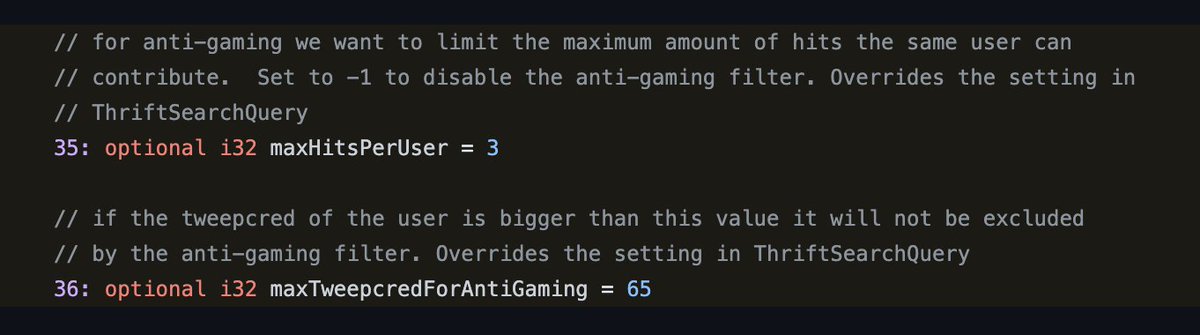
3/ Karma. La reputación de tu cuenta es importantísima para el algoritmo.
💡 Lo que se conoce como el "Tweepcred".
💡 Lo que se conoce como el "Tweepcred".

4/ Si tu karma-tweepcred es superior a 65, estás de enhorabuena. Por debajo de eso, estás fuera de juego. El shadow ban que sufrí la semana pasada ha debido mandar mi reputación a los infiernos.

5/ Interactuar con cuentas de baja calidad, PENALIZA.
Es decir, en teoría, simplemente por charlar con alguien con un ratio de seguidores regulero, tu karma disminuirá.
Pero como ya dije ayer, yo seguiré hablando con todo el mundo. Me niego a plegarme a los designios de X.
Es decir, en teoría, simplemente por charlar con alguien con un ratio de seguidores regulero, tu karma disminuirá.
Pero como ya dije ayer, yo seguiré hablando con todo el mundo. Me niego a plegarme a los designios de X.

6/ Los links salientes penalizan (lo que ya sabíamos, pero ahora confirmado). En cambio las imágenes o vídeos tiene un boost positivo.
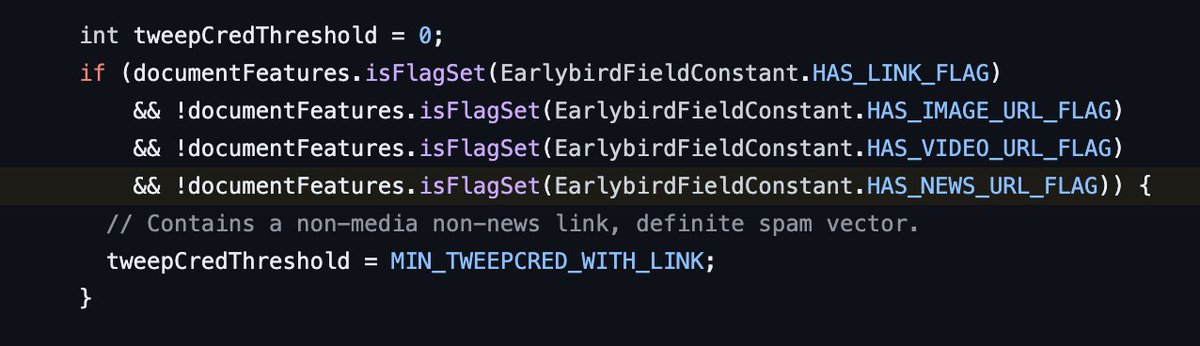
7/ ¿Cómo decaen tus posts en el tiempo? ¡Si en las 6 primeras horas no viraliza lo vas a tener complicado!

LINKs:
🔗 Posts oficiales de X:
1/ blog.twitter.com
2/ blog.twitter.com
3/ ueo-workshop.com
4/ #L176" target="_blank" rel="noopener" onclick="event.stopPropagation()">github.com
🔗 Fuentes externas a X:
Este análisis es brutal y es el esquema que he seguido en mi hilo: tweethunter.io
🔗 Posts oficiales de X:
1/ blog.twitter.com
2/ blog.twitter.com
3/ ueo-workshop.com
4/ #L176" target="_blank" rel="noopener" onclick="event.stopPropagation()">github.com
🔗 Fuentes externas a X:
Este análisis es brutal y es el esquema que he seguido en mi hilo: tweethunter.io
ueo-workshop.com/wp-content/upl…

tweethunter.io/blog/twitter-a…
How does the twitter algorithm work (short and long answers)
A deep analysis of how the Twitter algorithm works

blog.twitter.com/engineering/en…
Twitter's Recommendation Algorithm
Twitter aims to deliver you the best of what’s happening in the world right now. This blog is an int...

blog.twitter.com/en_us/topics/c…
A new era of transparency for Twitter
At Twitter 2.0, we believe that we have a responsibility, as the town square of the internet, to mak...
github.com/twitter/the-al…
¡Fin del larguísimo hilo!
Ahora dale like, RT, reply, bookmark, haz el pino puente en mi cluster y ponle una vela a Santo Elon para que no me meta un shadow ban por abrir delante vuestra LA CAJA DE PANDORA del conocimiento.
¡Espero que hayáis aprendido mucho!
Ahora dale like, RT, reply, bookmark, haz el pino puente en mi cluster y ponle una vela a Santo Elon para que no me meta un shadow ban por abrir delante vuestra LA CAJA DE PANDORA del conocimiento.
¡Espero que hayáis aprendido mucho!
جاري تحميل الاقتراحات...