

عندما أعلنت OpenAI عن قدرة #GPT4 على قراءة الصور وتحليلها، لم تطلقه للعموم، بل ذكرت أن الميزة تحت الاختبار حالياً
هذا لم يمنع المتحمسين في عالم المصادر المفتوحة من اقتباس الفكرة!
اذهب إلى الصفحة التالية، وسأشرح لك في التغريدة التالية ما ستراه!
llava-vl.github.io
هذا لم يمنع المتحمسين في عالم المصادر المفتوحة من اقتباس الفكرة!
اذهب إلى الصفحة التالية، وسأشرح لك في التغريدة التالية ما ستراه!
llava-vl.github.io
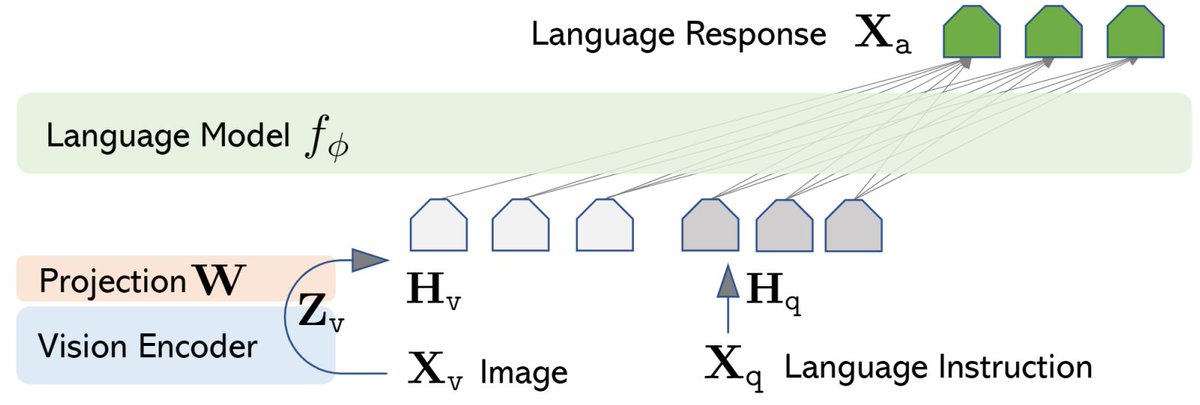
LLaVA هو نموذج جديد متعدد الوسائط مدربا من طرف إلى طرف يجمع بين vision encoder و Vicuna لفهم الصور واللغة، تحقيق قدرات دردشة رائعة تحاكي #GPT4 متعدد الوسائط
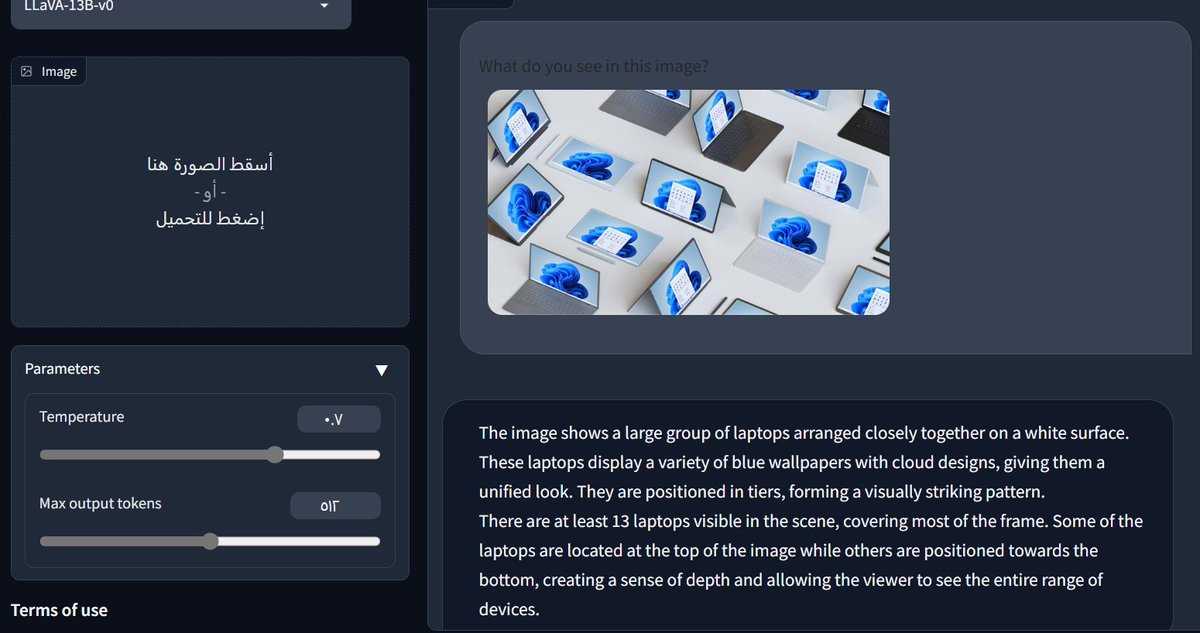
كما ترى في الصورة، تمكن من معرفة محتوى الصورة!
بالمناسبة، يقبل المطالبة باللغة العربية، لكن الإجابة ستكون بالإنجليزية
كما ترى في الصورة، تمكن من معرفة محتوى الصورة!
بالمناسبة، يقبل المطالبة باللغة العربية، لكن الإجابة ستكون بالإنجليزية
أعجبني دقة النموذج!
امم ليست دقيقة تماماً، لكنها مقبولة
سألته: ماذا يوجد في الشاشة على اللاب توب في الصورة؟
أجابني:
امم ليست دقيقة تماماً، لكنها مقبولة
سألته: ماذا يوجد في الشاشة على اللاب توب في الصورة؟
أجابني:

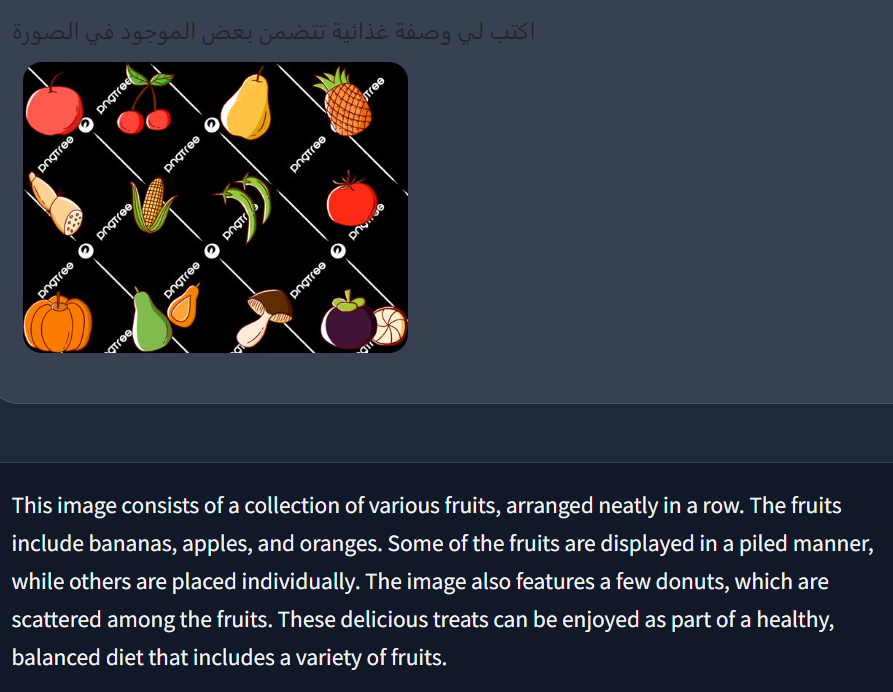
طلبت منه طلباً آخر:
اكتب لي وصفة غذائية تتضمن بعض الموجود في الصورة
وكان رده:
اكتب لي وصفة غذائية تتضمن بعض الموجود في الصورة
وكان رده:

أعجبني في النموذج أيضاً، أنه سريع جداً!
ثواني ويجيب على استفسارك
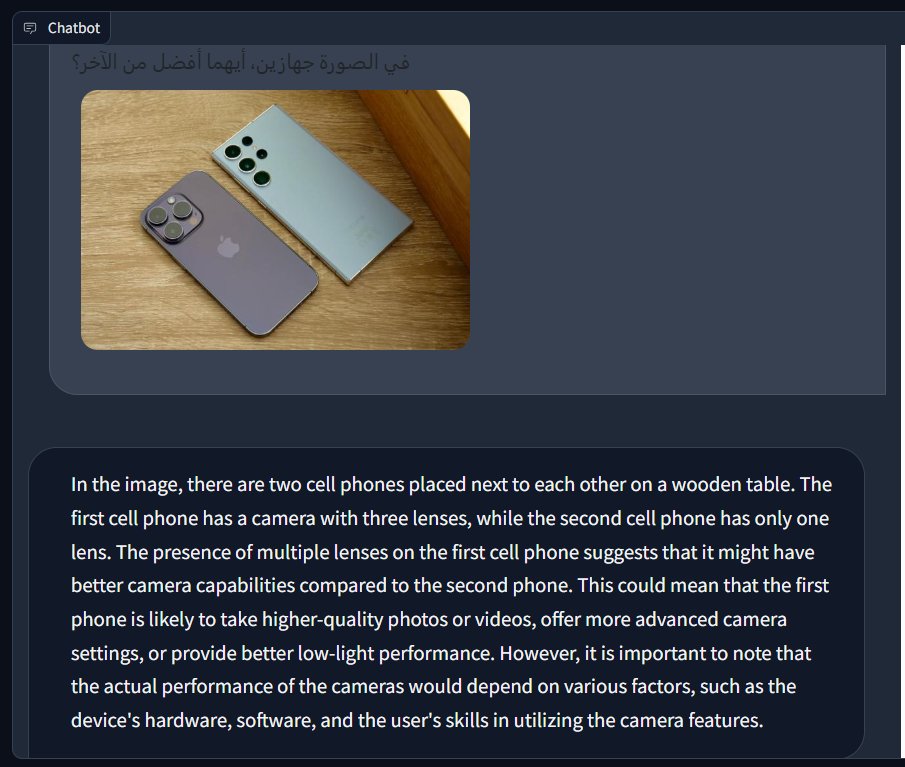
قررت آخذ النموذج إلى مستوى أعلى:
المطالبة: في الصورة جهازين، أيهما أفضل من الآخر؟
للأسف، لم يتعرف على الأجهزة!
ثواني ويجيب على استفسارك
قررت آخذ النموذج إلى مستوى أعلى:
المطالبة: في الصورة جهازين، أيهما أفضل من الآخر؟
للأسف، لم يتعرف على الأجهزة!
ورغم ذلك، ومن خلال تجاربي
هذا أفضل نموذج متاح يتعامل مع الصور، وفق الطريقة الموعودة في #GPT4
سريع، ويدعم إسقاط الصور، سواء من جهازك أو من صفحة ويب أخرى.
جربه، لن تندم أبداً
llava-vl.github.io
هذا أفضل نموذج متاح يتعامل مع الصور، وفق الطريقة الموعودة في #GPT4
سريع، ويدعم إسقاط الصور، سواء من جهازك أو من صفحة ويب أخرى.
جربه، لن تندم أبداً
llava-vl.github.io
جاري تحميل الاقتراحات...