

في مشاريع التعلم العميق وتعلم الآلة كمثال تصنيف الصور قد تكون البيانات غير كافية للحصول على نتائج مُرضية.
يوجد عدة طرق لزيادة البيانات.
من أسهلها في التنفيذ وغالباً تعطي نتائج جيدة
ال Data Augmentation
يوجد عدة طرق لزيادة البيانات.
من أسهلها في التنفيذ وغالباً تعطي نتائج جيدة
ال Data Augmentation
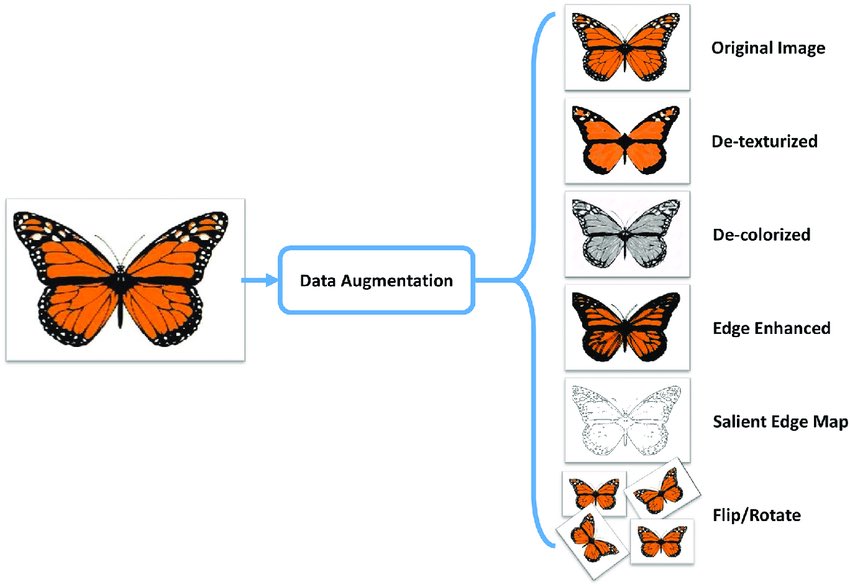
ال Data Augmentation هي عملية تمكنك من الحصول على نسخ/عينات متعددة من صورة في ال dataset الخاص بك
ممكن تعمل لها تدوير ١٠٪ أو عكس الاتجاه flipping أو تقريب zoom الخ
ممكن تعمل لها تدوير ١٠٪ أو عكس الاتجاه flipping أو تقريب zoom الخ

ال DA ممكن نحتاجها في حالة ال underfitting بحيث أن البيانات قليلة ونتيجة التدريب سيئة. فيتم زيادة العينات. حتى يتمكن النمودج من اكتشاف العلاقة بشكل صحيح.
أيضا في ال overfitting بيانات التدريب تحتاج بعض ال noisy والتي يمكن انتاجها من الDA حتى يمكن التنبؤ ببيانات الاختبار بشكل أفضل
أيضا في ال overfitting بيانات التدريب تحتاج بعض ال noisy والتي يمكن انتاجها من الDA حتى يمكن التنبؤ ببيانات الاختبار بشكل أفضل
يوجد مصطلح أخر يستخدم لتوليد عينات جديدة.
ال Synthetic data
هذا يختلف عن ال Data Augmentation
البيانات الاصطناعية يتم توليدها من خلال نماذج
Generative Adversarial Networks
بحيث يتم تدريب نمودج على صور مختلفة ويمكن لهذا النموذج توليد عينة جديدة ليست من real-world مثل DeepAI وغيره
ال Synthetic data
هذا يختلف عن ال Data Augmentation
البيانات الاصطناعية يتم توليدها من خلال نماذج
Generative Adversarial Networks
بحيث يتم تدريب نمودج على صور مختلفة ويمكن لهذا النموذج توليد عينة جديدة ليست من real-world مثل DeepAI وغيره
يمكن أيضاً توليد ال Synthetic data من خلال نماذج رياضية أو احصائية مثل SMOTE oversampling
هذي الطريقة تعتمد على البحث عن العينات الأقرب من خلال k nearest neighbors يتم توليد عينات جديدة منها.
هذي الطريقة تعتمد على البحث عن العينات الأقرب من خلال k nearest neighbors يتم توليد عينات جديدة منها.
ال SMOTE والتقنيات المشابهه لها قد تندرج تحت ال DA لكنه في الغالب يستخدم للبيانات التي على شكل جدول وهدفه الرئيسي حل مشكلة عدم توازن البيانات بحيث تكون عينات ال classes غير متوازنة imbalanced dataset
ال Data Augmentation تعمل على معالجة الصور لتكوين صور جديدة من نفس البيانات.
ال Data Augmentation تعمل على معالجة الصور لتكوين صور جديدة من نفس البيانات.
هناك عدة طرق لتنفيذ ال Data Augmentation
فيمكن تنفيذها من خلال
TensorFlow tf.image
أو Keras preprocessing layers
أيضا ImageDataGenerator
وهناك كذلك استراتجيات مختلفة لتنفيذها لكن نركز على طريقتين:
فيمكن تنفيذها من خلال
TensorFlow tf.image
أو Keras preprocessing layers
أيضا ImageDataGenerator
وهناك كذلك استراتجيات مختلفة لتنفيذها لكن نركز على طريقتين:
١- خارج عملية التدريب:لدينا ١٠٠٠ صورة. ويتم إنشاء مثلاً ٤٠٠٠ صورة من ال ١٠٠٠ الأصلية وذلك بشكل مستقل كعملية معالجة مسبقة
وتصبح الdataset ٥ آلاف
تناسب هذه في حالات تكون الdataset مُجمعة من عدة مصادر وتريد زيادة جزء معين من البيانات.
أو تريد تكبير ال dataset ونشرها ليستفيد الغير
وتصبح الdataset ٥ آلاف
تناسب هذه في حالات تكون الdataset مُجمعة من عدة مصادر وتريد زيادة جزء معين من البيانات.
أو تريد تكبير ال dataset ونشرها ليستفيد الغير
هذا الكود مثال على الطريقة الأولى. ويمكنك مع عمل Augmentation وحفظ الصور في نفس المجلد لكل class
github.com
github.com
٢- داخل عملية التدريب
هذه الطريقة لاتزيد العينات فمثلا لدينا ١٠٠٠ عينة، يقوم الModel أثناء عملية التدريب بتطبيق مجموعات عمليات لل DA في كل epoch. بمعنى في كل iteration يتم توليد صور من الصورة الأصلية ويتدرب عليها النموذج بدون حفظها في ال Dataset
هذه الطريقة لاتزيد العينات فمثلا لدينا ١٠٠٠ عينة، يقوم الModel أثناء عملية التدريب بتطبيق مجموعات عمليات لل DA في كل epoch. بمعنى في كل iteration يتم توليد صور من الصورة الأصلية ويتدرب عليها النموذج بدون حفظها في ال Dataset
أخير ال DA تُطبق على بيانات التدريب. وتكون بيانات الاختبار معزولة حتى يكون النموذج أدق.
هذه بعض المصادر لتفاصيل أكثر عن ال DA
medium.com
baeldung.com
neptune.ai
هذه بعض المصادر لتفاصيل أكثر عن ال DA
medium.com
baeldung.com
neptune.ai
جاري تحميل الاقتراحات...