

مقال جميل من discord بيتكلموا عن ازاي بيخزنوا ترليونات من الرسائل وعن المشاكل اللي قابلتهم مع Csssandra والحلول اللي عملوها واللي منها انهم نقلوا لScyllaDB بدل Cassandra واستخدموا Rust في كذا حتة فرق معاهم جدا.
1/13
1/13
والمقال ده يعتبر الحزء التاني لانهم في 2017 كتبوا عن انهم نقلوا من MongoDB لCassandra لانهم كانوا عايزين حاجة تكون scalable وfault-tolerant ومحتاجة maintenance اقل نسبيا.
2/13
2/13
في 2017 كان عندهم 12 cassandra node فيها مليارات الرسائل بس في نهاية 2020 كان عندهم 177 node فيهم ترليونات من الرسائل.
3/13
3/13
في Cassandra الreads اغلي من الwrites لان الwrites بتتكتب في commit log وmemtable وبيتعملهم flush للdisk.
انما الreads بتحتاج تquery الmemtable وامتر من SSTable (الfiles اللي علي الdisk).
4/13
انما الreads بتحتاج تquery الmemtable وامتر من SSTable (الfiles اللي علي الdisk).
4/13
المشكلة اللي قابلتهم هي الhot partitions وده معناه ان partition/shard يبقي عليه load كبير اكتر من باقي الpartitions وده بيكون بسبب مثلا ان في سيرفرات (جروبات) علي discord فيها ناس اكتر ومثلا tag زي "everyone" ممكن يعمل كمبة reads ‘لي partition واحد ويسبب الhot partition.
5/13
5/13
مشكلة تانبة قابلتهم وهي الSSTables compaction ودي عملية زي الcompressing بتدمج اكتر من SSTable مع بعض عشان يحسن سرعة الreads.
فبسبب الcompactions كان بيحصل زيادة في الlatency فحلوا المشكلة دي بانهم ميخلوش الnode اللي بتعمل compaction تاخد queries لحد ما تخلص الcompaction.
6/13
فبسبب الcompactions كان بيحصل زيادة في الlatency فحلوا المشكلة دي بانهم ميخلوش الnode اللي بتعمل compaction تاخد queries لحد ما تخلص الcompaction.
6/13
قضوا وقت كتير في انهم عملوا tuning للJVM garbage collector والheap settings عشان الGC كان بيسبب زيادة في الlatency وكان ساعات بيعمل pauses كبيرة تخلي حد يعمل reboot للnode عشان ترجع تشتغل تاني.
7/13
7/13
ده كان من اقوي الاسباب اللي خلاهم ينقلوا لScyllaDB اللي مكتوبة بC++ فمفيهاش Garbage Collection وكانت بتوعد بperformance احسن اسرع repairs ودي عملية بتبقي في الbackground بتتأكد ان الdata معمولها sync بشكل صحيح بين الnodes.
8/13
8/13
مشكلة الhot partition اللي قابلتهم في Cassandra كلنوا بيحلوها بdata services ودي layer بين الservers والdatabase clusters ومكتوبة بRust وبيستخدموا Tokio عشان تبقي asynchronous.
كل query ليها gRPC endpoint ومفيش business logic في الdata services.
9/13
كل query ليها gRPC endpoint ومفيش business logic في الdata services.
9/13
الهدف من الموضوع ده ان لو في امتر من query لنفس الrecord فتبقي query واحدة للdatabase.
اول user بيعت الquery بيعمل worker task للquery ولو في user تاني بعت query لنفس الrecord بيsubscribe للworker task ده وهو بيرجع الrecords لكل الsubscribers.
10/13
اول user بيعت الquery بيعمل worker task للquery ولو في user تاني بعت query لنفس الrecord بيsubscribe للworker task ده وهو بيرجع الrecords لكل الsubscribers.
10/13
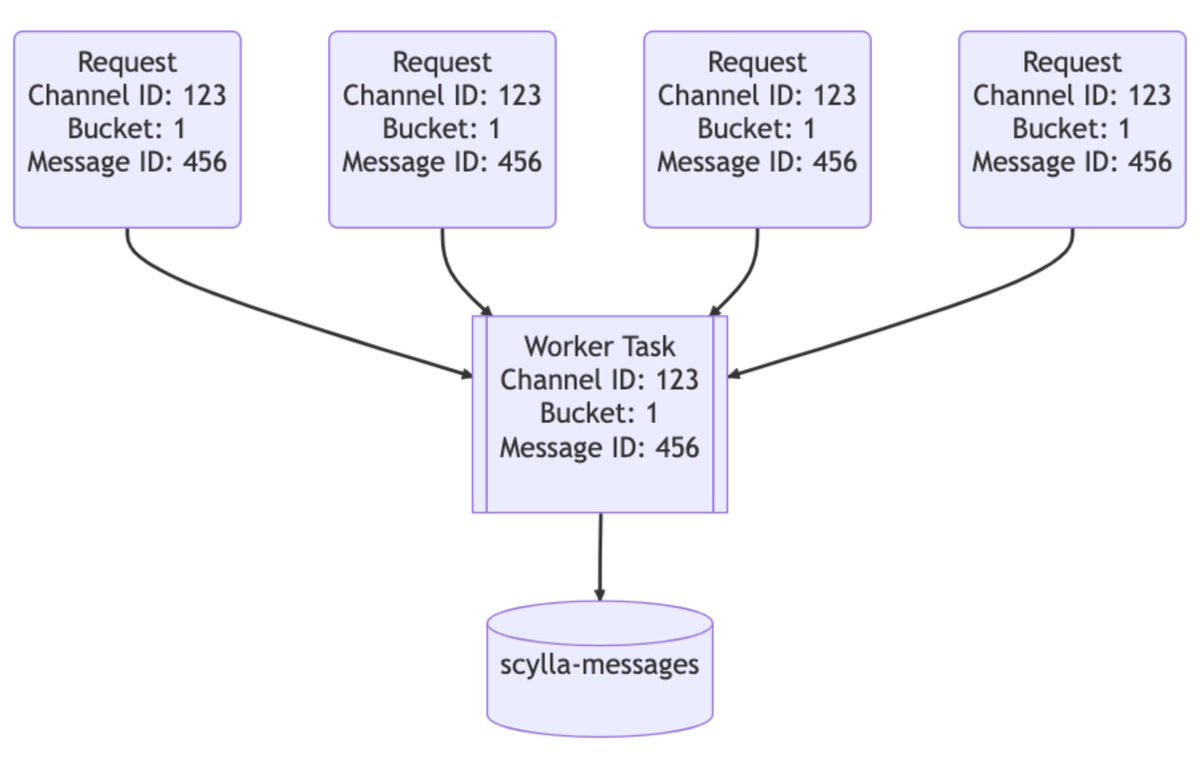
طبعا ده مفيد جدا لو تعمل everyone mention فالusers هيفتحوا يجيبوا نفس الرسالة ويسببوا الhot partition.
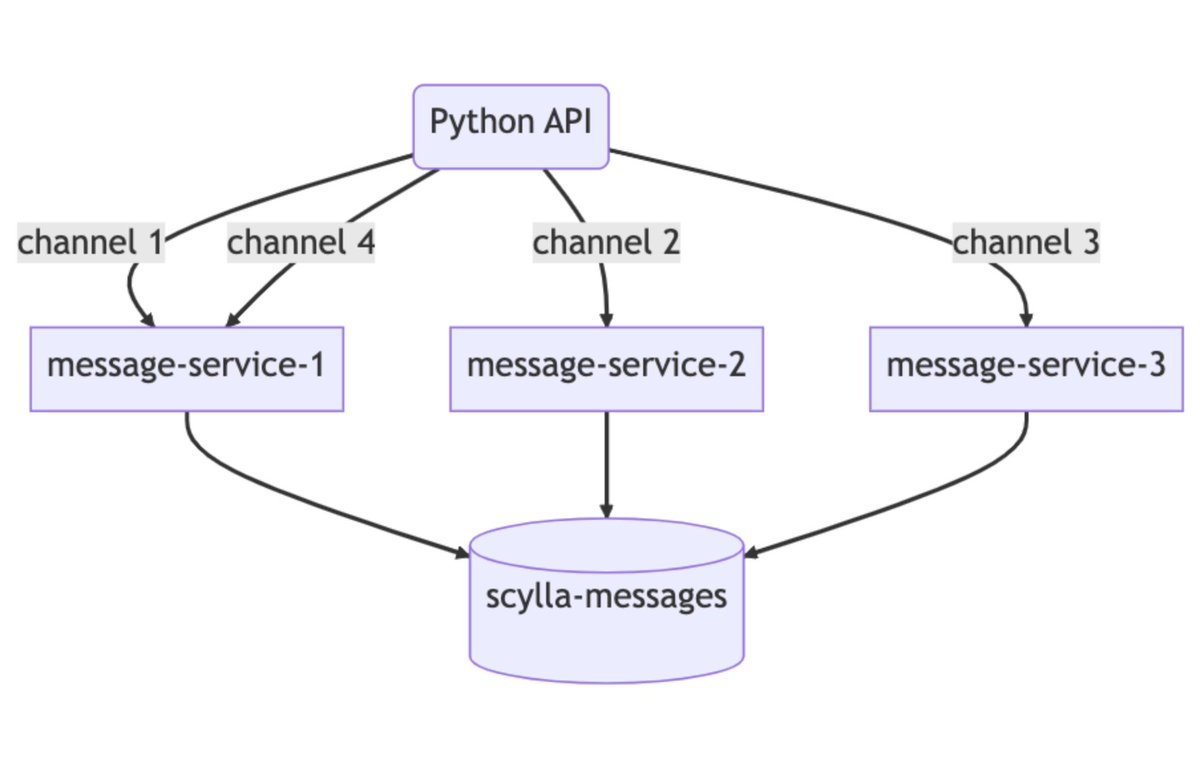
وعملوا consistent hash-based routing للdata services بالchannel id عشان الqueries لنفس الchannel تروع لنفس الinstance فيقدروا يستفيدوا باكبر قدر من الconcurrency.
11/13
وعملوا consistent hash-based routing للdata services بالchannel id عشان الqueries لنفس الchannel تروع لنفس الinstance فيقدروا يستفيدوا باكبر قدر من الconcurrency.
11/13
حاليا بدل ما كان عندهم 177 Cassandra nodes بقي عندهم 72 ScyllaDB nodes وكل واحدة فيها 9TB علي الdisk انما Cassandra كان حوالي 4TB.
بالنسبة للp99 latencies:
historical messages:
Cassandra => 40-125ms
ScyllaDB => 15ms
message insert:
Cassandra => 5-70ms
ScyllaDB => 5ms
12/13
بالنسبة للp99 latencies:
historical messages:
Cassandra => 40-125ms
ScyllaDB => 15ms
message insert:
Cassandra => 5-70ms
ScyllaDB => 5ms
12/13
مقالة بتشرح الwrites والreads والrepairs في Cassandra:
allaboutcode.medium.com
allaboutcode.medium.com

جاري تحميل الاقتراحات...