

what is ControlNet and how does it work? 👇

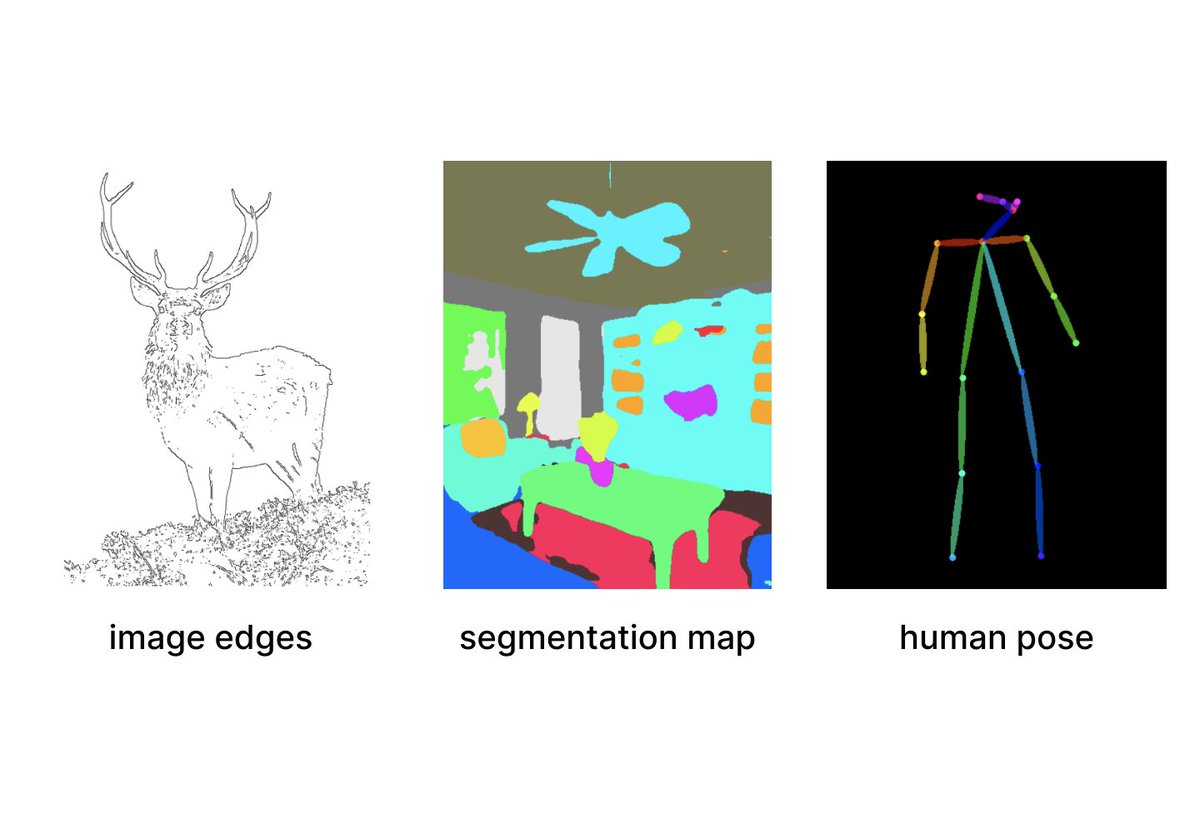
ControlNet is a method that can be used to condition diffusion models on arbitrary input features, such as image edges, segmentation maps, or human poses.
the following is a general representation of ControlNet's architecture.
first, it clones the weights of a diffusion model. Then, it trains the cloned weights to control the original model with the task from the input condition.
first, it clones the weights of a diffusion model. Then, it trains the cloned weights to control the original model with the task from the input condition.

the goal of this architecture is to keep as much as possible all the knowledge learned by the original model.
the trainable network learns how to perform the control in a progressive way thanks to the use of zero convolutions.
the trainable network learns how to perform the control in a progressive way thanks to the use of zero convolutions.
zero convolutions are 1D convolutions with weights and biases initialized to 0s.
note how at the beginning of the training ControlNet will not affect the original network at all, but as it gets trained it will progressively start influencing the generation with the condition.
note how at the beginning of the training ControlNet will not affect the original network at all, but as it gets trained it will progressively start influencing the generation with the condition.
the following is a representation of ControlNet's architecture when used with Stable Diffusion

in this case, the cloned networks are the U-Net encoder/middle layers, and the results of the each trainable copy are fed in each middle/decoder block.
it is worth mentioning that the authors used a convolutional architecture to encode the condition image before feeding it within the cloned U-Net.
the use of zero convolutions while training results in a funny behavior that the authors name “sudden convergence phenomenon”, where the model is suddenly able to follow the input conditions, as depicted in the following image:
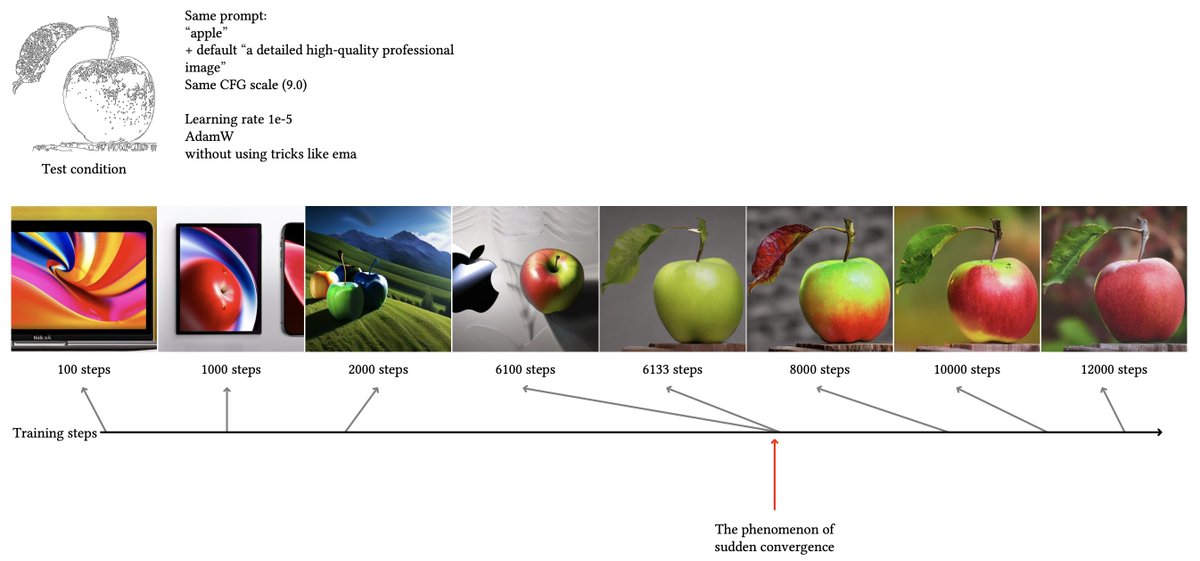
the way how this work enables us to control the structure from the images we generate is truly interesting.
here are some of our favorite results so far:
here are some of our favorite results so far:




big s/o to @lvminzhang for this mind-blowing work and for making it open to everyone.
we're adding this method to the KREA Canvas, can't wait to see what y'all create with it! ⚡️
1x1 convolutions, not 1D* :/
جاري تحميل الاقتراحات...