

ما هي GPT ؟
تغريدات متسلسلة 🧵
تغريدات متسلسلة 🧵

GPT
الحروف الأولى من
Generative Pre-trained Transformer
وباللغة العربية يمكن صياغته على أنه (المحوّلات التّوليديَّة المُدرَّبة مُسبقاً)
وتعتمد في عملها على التعلم الآلي والتمييز والتنبؤ بالكلمات التالية من خلال المدخلات السابقة وذلك لإنتاج نصوص تشبه كثيراً النصوص البشرية
الحروف الأولى من
Generative Pre-trained Transformer
وباللغة العربية يمكن صياغته على أنه (المحوّلات التّوليديَّة المُدرَّبة مُسبقاً)
وتعتمد في عملها على التعلم الآلي والتمييز والتنبؤ بالكلمات التالية من خلال المدخلات السابقة وذلك لإنتاج نصوص تشبه كثيراً النصوص البشرية
GPT باختصار:
- نموذج لغة الانحدار الذاتي الذي يستخدم التعلم العميق لبناء نص يشبه النصوص التي ينشئها الإنسان
-عملية الانحدار الذاتي هي العملية التي تعتمد فيها القيمة الحالية على القيمة السابقة مباشرة.
- إنه نوع من برنامج الإكمال التلقائي الذي يتنبأ بما يمكن أن يحدث بعد ذلك
- نموذج لغة الانحدار الذاتي الذي يستخدم التعلم العميق لبناء نص يشبه النصوص التي ينشئها الإنسان
-عملية الانحدار الذاتي هي العملية التي تعتمد فيها القيمة الحالية على القيمة السابقة مباشرة.
- إنه نوع من برنامج الإكمال التلقائي الذي يتنبأ بما يمكن أن يحدث بعد ذلك
أطلقت شركة openai اصدارها الأول من عائلة GPT في نوفمير 2018م، وكانت كالآتي:
⁃GPT-1 في 2/2018
⁃GPT-2 في 2/2019
⁃GPT-3 في 2/2020
⁃يتوقع أن يأتي GPT-4 قريباً
⁃GPT-1 في 2/2018
⁃GPT-2 في 2/2019
⁃GPT-3 في 2/2020
⁃يتوقع أن يأتي GPT-4 قريباً
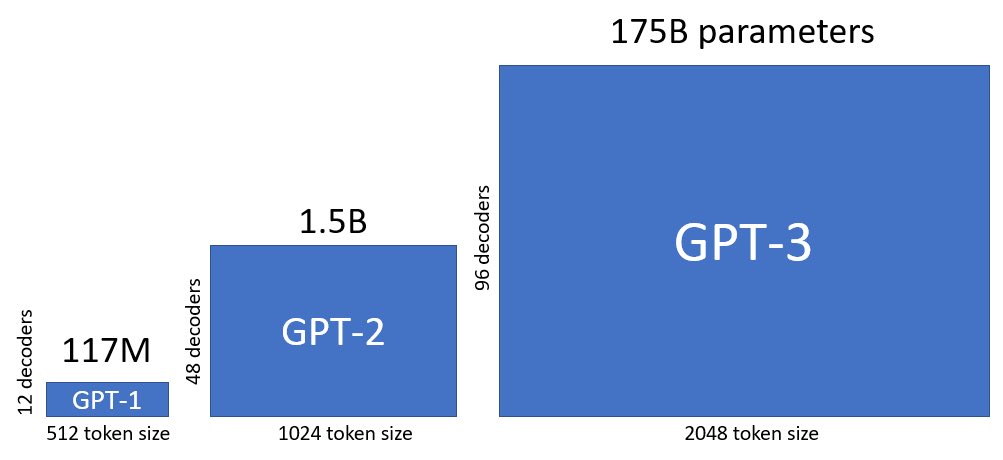
أما عن المعلمات
(نقاط التمييز في مجتمع البيانات) فهي كالآتي:
⁃GPT-1 تحتوي (117 مليون معلمة)
⁃GPT-2 تحتوي (1.5 مليار معلمة)
⁃GPT-3 تحتوي (175 مليار معلمة)
⁃
يقال أن GPT-4 (سيكون 1 ترليون معلمة وقال رئيس openai أنه هراء وشائعات)
(نقاط التمييز في مجتمع البيانات) فهي كالآتي:
⁃GPT-1 تحتوي (117 مليون معلمة)
⁃GPT-2 تحتوي (1.5 مليار معلمة)
⁃GPT-3 تحتوي (175 مليار معلمة)
⁃
يقال أن GPT-4 (سيكون 1 ترليون معلمة وقال رئيس openai أنه هراء وشائعات)


الاختلاف بينها ليس في المعلمات فقط
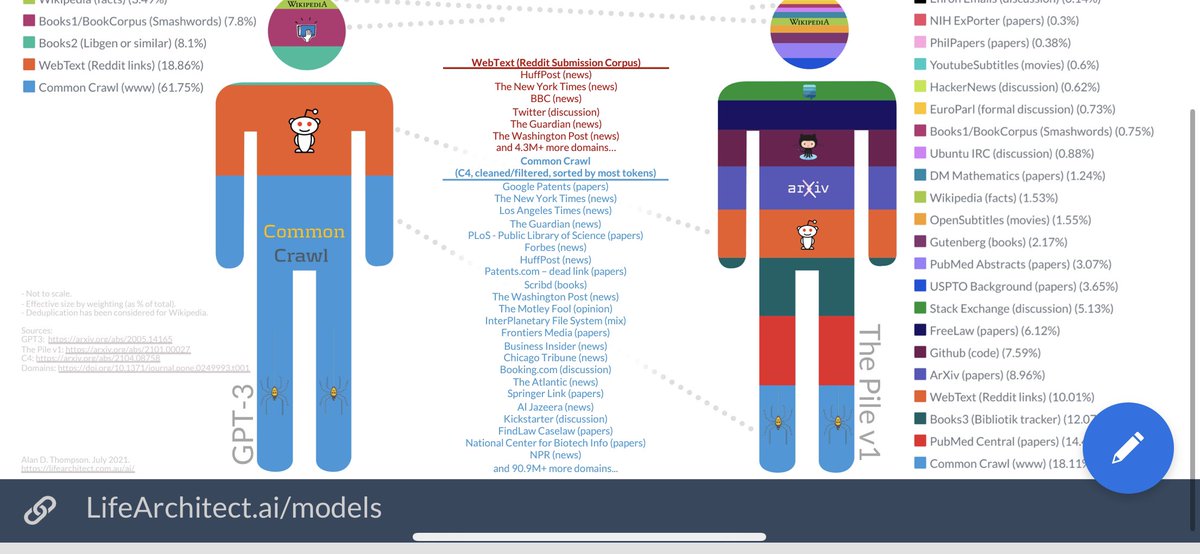
ولكن كمية البيانات والنصوص الطويلة التي تدربت عليها، حيث
•GPT-1: تدرب على بيانات تضم 40Gb من النصوص الـE
•GPT-2: تدرب على بيانات تضم 40Gb من النصوص الـE
•GPT-3: تدرب على بيانات تضم 570Gb من النصوص الـE ولغات أخرى كالعربية.
ولكن كمية البيانات والنصوص الطويلة التي تدربت عليها، حيث
•GPT-1: تدرب على بيانات تضم 40Gb من النصوص الـE
•GPT-2: تدرب على بيانات تضم 40Gb من النصوص الـE
•GPT-3: تدرب على بيانات تضم 570Gb من النصوص الـE ولغات أخرى كالعربية.
يقول رئيس OpenAI إن GPT-4 سيكون قادرًا أيضًا على التعامل مع المزيد من السياق.
الحد الحالي لـ GPT-3 هو 2048 رمزًا ، في حين أن Codex's هو 4096 رمزًا.
الحد الحالي لـ GPT-3 هو 2048 رمزًا ، في حين أن Codex's هو 4096 رمزًا.
هناك نسخة خاصة (تحمل الاختصار (RUGPT-3) خاصة بالتعامل مع البيانات التي تكون باللغة العربية وهذه النسخة غير متاحة للجمهور وهي مخصصة للشركات التي تتعاون وتتعامل مع openai ويمكن الحصول عليها بالتواصل مع الشركة.
مقارنة نماذج اللغة حتى ابريل/2022
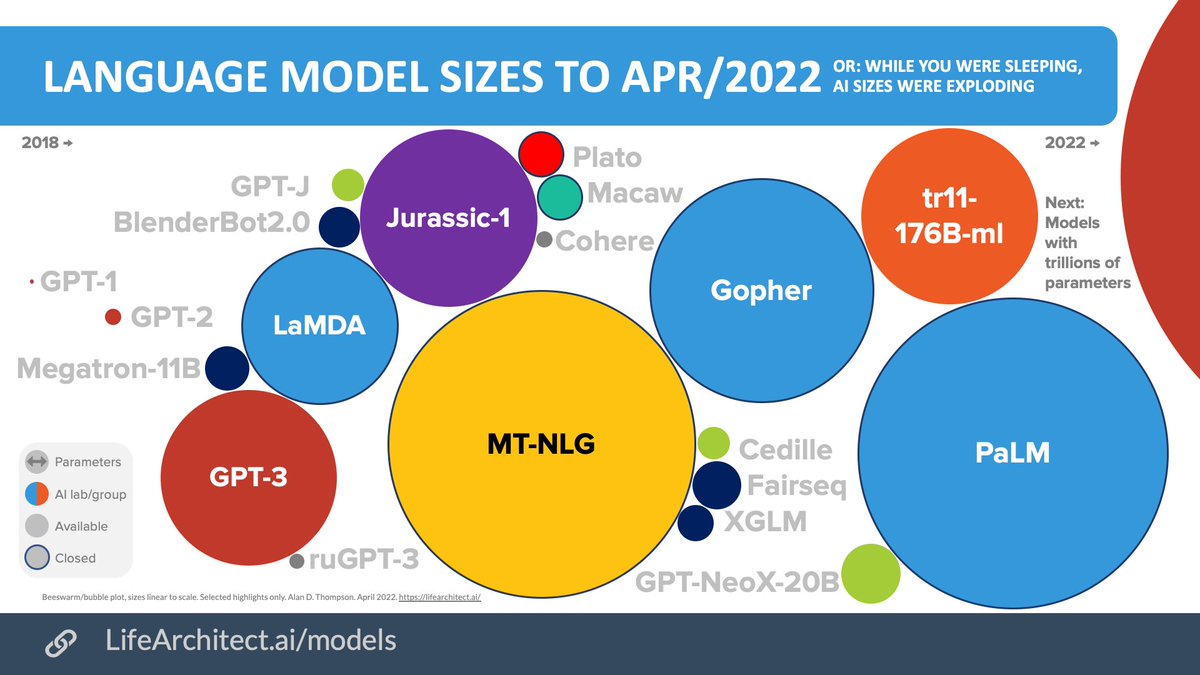
رسم بياني يصور المشهد الحالي لنموذج اللغة الكبيرة (LLM)

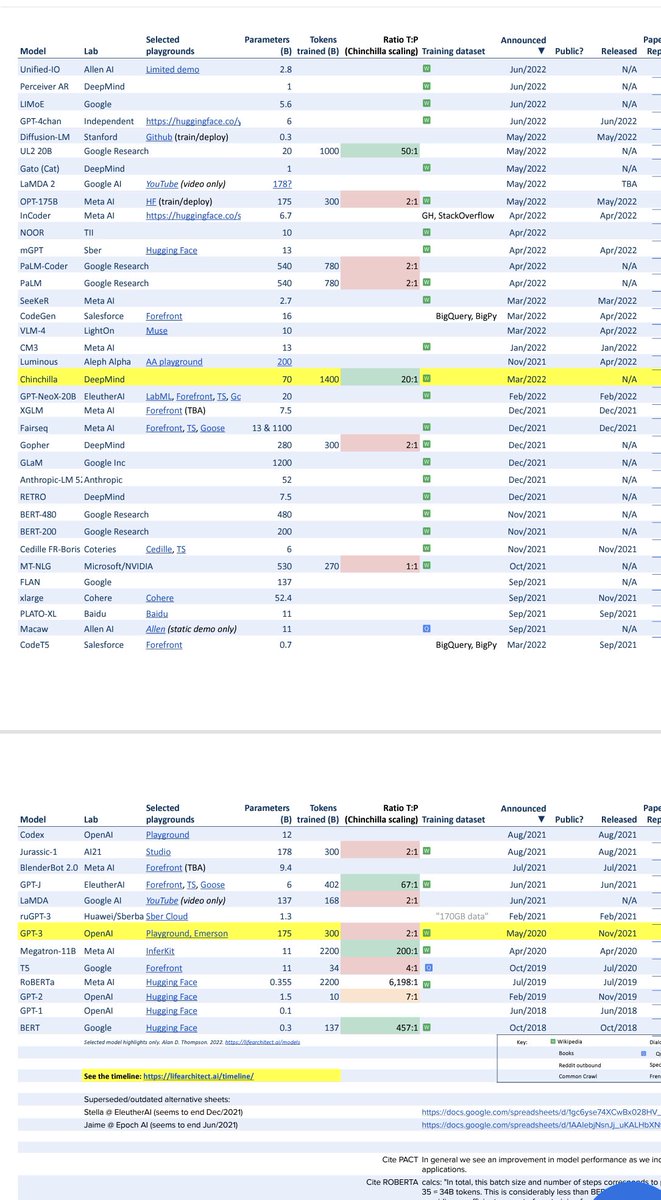
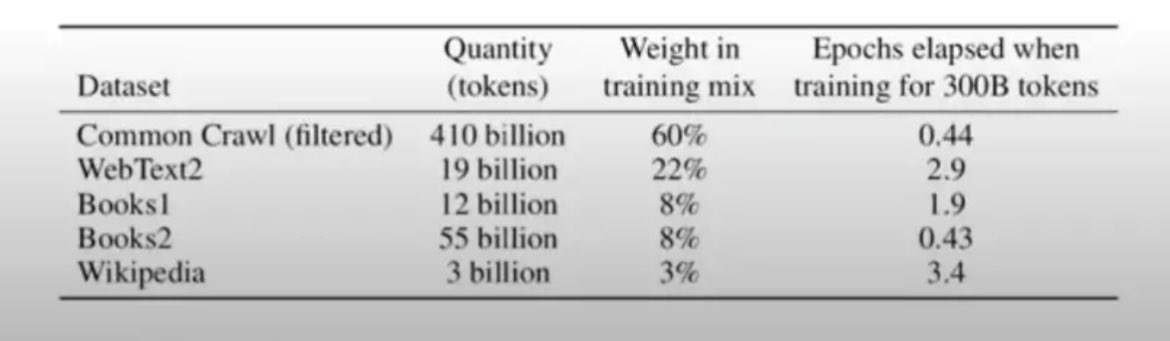
من أين حصل GPT-3 على البيانات ؟
لاحظوا النسب في الجدول الأول👇🏻
حصل على 3% من ويكيبيديا
لاحظوا النسب في الجدول الأول👇🏻
حصل على 3% من ويكيبيديا

جاري تحميل الاقتراحات...