

في الأيام الماضية #ChatGPT أدهش العالم بسهولة التخاطب معه كذكاء اصطناعي وبدقة وتنوع المعلومات اللي يقدمها. حبيت آخذ نظرة عليه، ما هو من وجهة نظر المستخدم لكن من وجهة نظر المبرمج.
من الطرق اللي أحب التعلم من خلالها هي إني أحاول أشرح المعلومة لنفسي. ولذلك راح أكتب هذا الثريد:
👇
من الطرق اللي أحب التعلم من خلالها هي إني أحاول أشرح المعلومة لنفسي. ولذلك راح أكتب هذا الثريد:
👇
لما ننظر لجوهر ChatGBT نلقى إنه في جوهره عبارة عن prompt يتم إدخاله من المستخدم، و completion يتم إعطاءه. المودل يحتاج يفهم البرومبت منك حتى يقدر يعطيك كومبليشن ملائم وبدرجة ثقة معينة، وطريقة فهمه تكون عن طريق تجزئة النص إلى tokens. وتقدر إنك تقود عملية الفهم بتضمين كلمات إضافية.
الحين ندخل على الكود مباشرة أفضل..
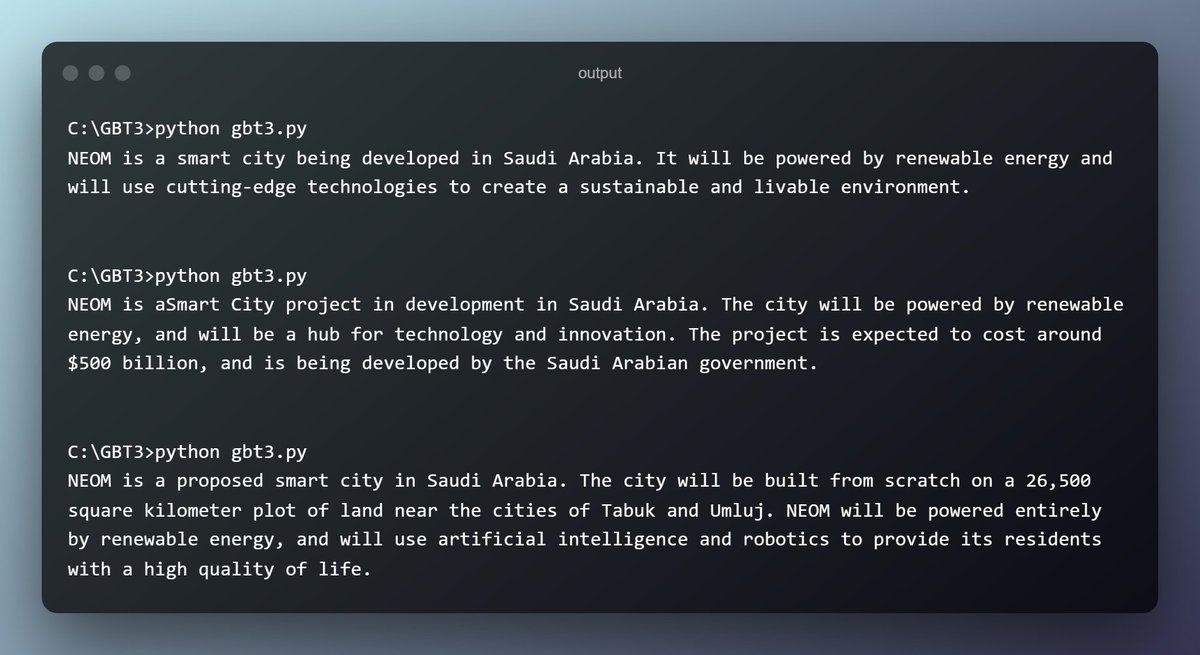
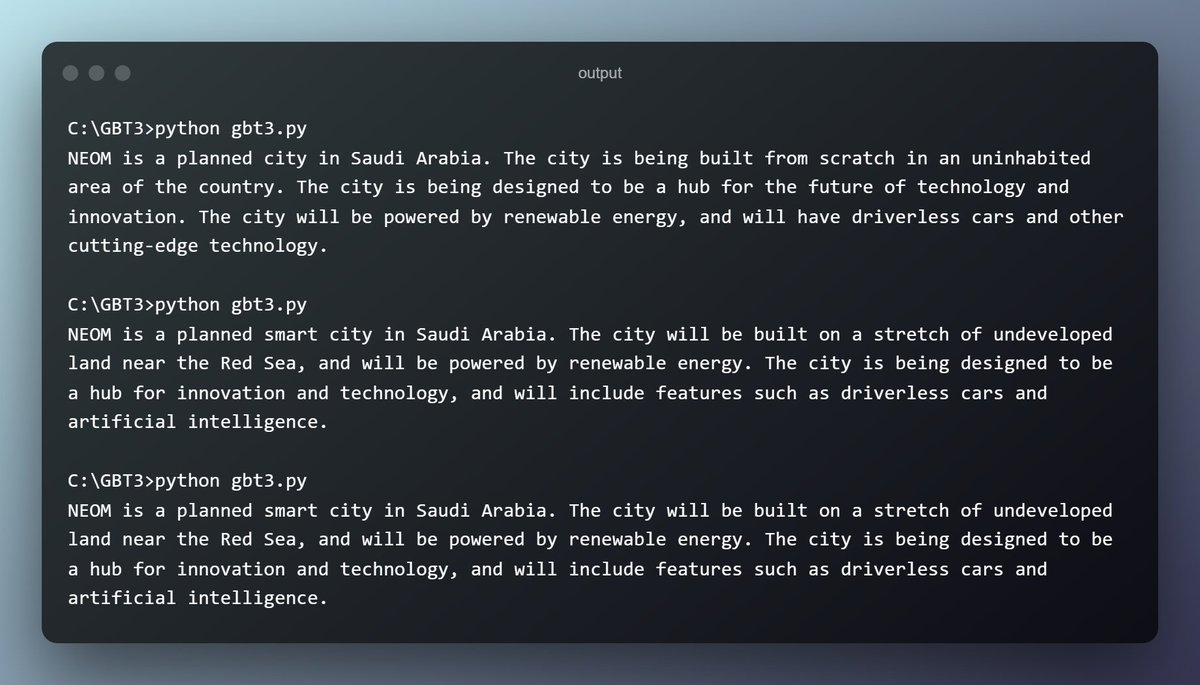
حتى نطلب كومبليشن نستدعي openai.Completion.create ونعطيها عدد من الـ arguments. راح أوقف عندها واحدة واحدة.. لكن قبل، أبي أسوي run للكود ثلاث مرات متتالية ونشوف وش يعطينا.
كلها إجابات منطقية.. لكن ليه كانت مختلفة مع إن البرومبت واحد؟
حتى نطلب كومبليشن نستدعي openai.Completion.create ونعطيها عدد من الـ arguments. راح أوقف عندها واحدة واحدة.. لكن قبل، أبي أسوي run للكود ثلاث مرات متتالية ونشوف وش يعطينا.
كلها إجابات منطقية.. لكن ليه كانت مختلفة مع إن البرومبت واحد؟
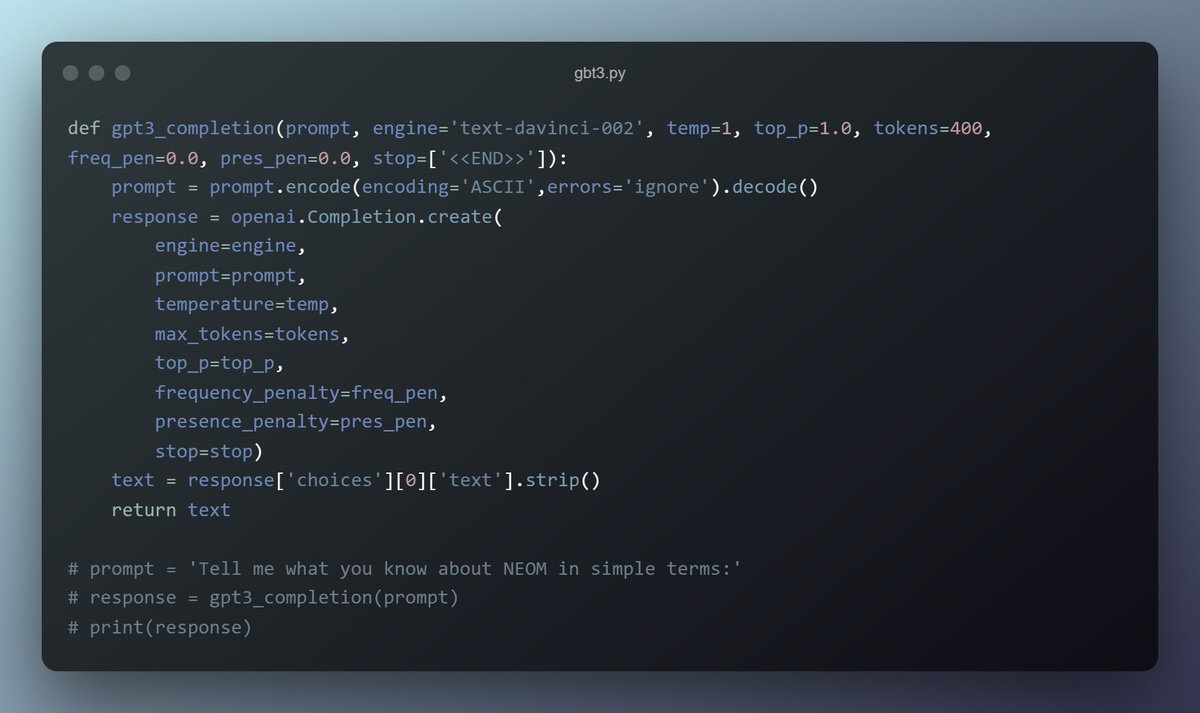
الـ arguments اللي تاخذها openai.Completion.create موضحة في الصورة أدناه. أولها، نحدد له المحرك من OpenAI (كل محرك له قدراته الخاصة وتسعيرته المختلفة). استعملت دافنشي وهو أقوى الموجود حالياً. ,وبعدين نعطيه البرومبت (سؤال المستخدم).
بعدها تجي التفاصيل المهمة.. ونبدأ مع Temp
بعدها تجي التفاصيل المهمة.. ونبدأ مع Temp

من أحد خصائص الكومبليشن هي الـ temperature، وهي قيمة تحكم ثقة المودل بالنتيجة اللي يتم اعطاءها. بمعنى، لو اننا أخذنا الـ temperature وحطينها 0 بدال 1.. راح يكون الناتج أجوبة شديدة التشابه ببعضها. مثال:
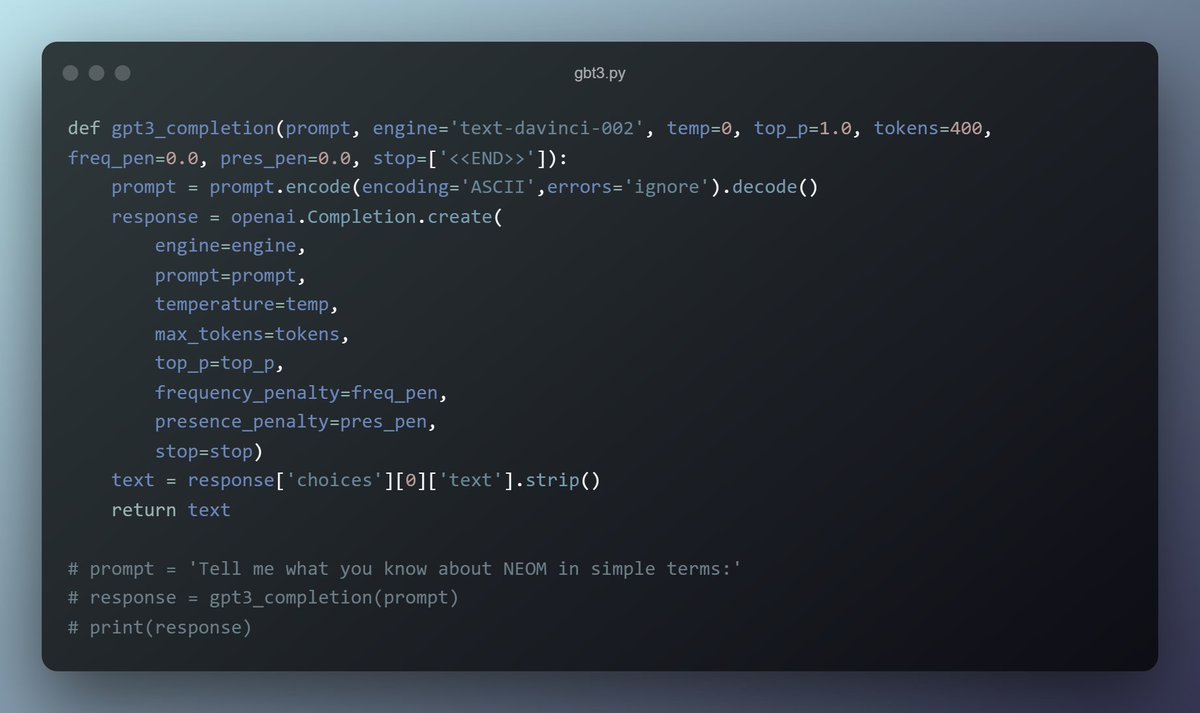
الـ argument الثانية هي max_tokens وهي مهمة حتى تتحكم بعدد التوكنز اللي يستعملها المودل ببناء الكومبليشن. كل ما زاد عدد التوكنز كل ما تشتت المودل في ايجاد الاجابة الأمثل. اللي فهمته انه المفروض انها ما تأثر كثير لما يكون الـ prompt قصير، بس تأثيرها يكبر كل ما كان الـ prompt أطول.
بعدها عندنا top_p وهذي فهمها احتاج مني شوية فهلوة :)
هي متعلقة بالـ probability distribution ومثل الـ temperature تاخذ من 0 الى 1. والرقم هذا يشكل النسبة المئوية من التوكنز اللي راح يتم أخذها بعين الاعتبار. لو حطيناه 0.5 معناه راح ياخذ التوكنز الـ 50% الأعلى ويغفل البقية.
هي متعلقة بالـ probability distribution ومثل الـ temperature تاخذ من 0 الى 1. والرقم هذا يشكل النسبة المئوية من التوكنز اللي راح يتم أخذها بعين الاعتبار. لو حطيناه 0.5 معناه راح ياخذ التوكنز الـ 50% الأعلى ويغفل البقية.
آخر ثنتين هم Frequency Penalty and Presence Penalty والفرق بينهم إن الأولى ترفع من أهمية التوكن بالنظر لعدد مرات تكراره من قبل، أما الثانية تقلل من أهمية التوكن إذا سبق وتكرر. التوازن بين الثنتين من المفترض إنه يخلق لك رد أفضل.
الخطوات اللي أحتاج أسويها في المضي قُدماً من هنا:
- النظر في إمكانية صنع واجهة مستخدم مبنية على أي شي غير Azure (الصفحة الحالية لـ ChatGBT مبنية باستعماله).
- طريقة تدريب الموديل على dataset خاصة (المودل يسمح بالـ Fine-tuning).
- النظر في إمكانية صنع واجهة مستخدم مبنية على أي شي غير Azure (الصفحة الحالية لـ ChatGBT مبنية باستعماله).
- طريقة تدريب الموديل على dataset خاصة (المودل يسمح بالـ Fine-tuning).
جاري تحميل الاقتراحات...