

ثريد يغطي اللي تعلمته من مسار
Deep learning Specialization الخاص بكورسيرا بالاضافة للمعلومات اللي درستها خلال الجامعة
المسار يتكون 5 كورسات جمعت اساسيات مجال التعلم العميق
بسم الله نبدأ
Deep learning Specialization الخاص بكورسيرا بالاضافة للمعلومات اللي درستها خلال الجامعة
المسار يتكون 5 كورسات جمعت اساسيات مجال التعلم العميق
بسم الله نبدأ

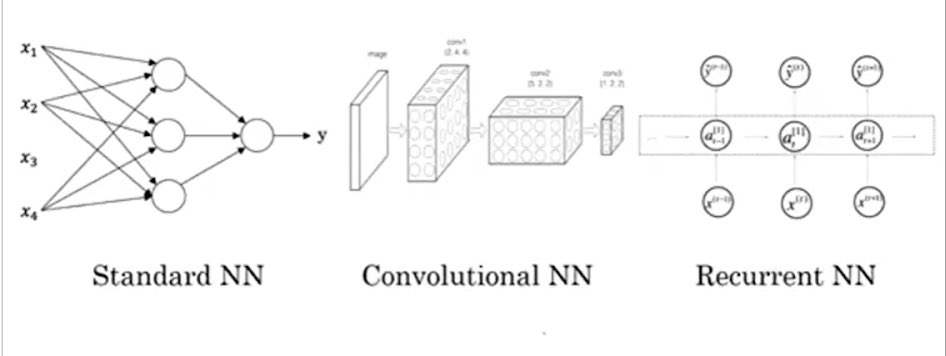
الكورس 1/ الشبكات العصبية ماهي ؟
فرع من فروع ML تعلم الالة تتكون من خلايا عصبية اصطناعية تحاكي خلايا دماغ الانسان توجد في ٣ طبقات
(طبقة المدخلات + الطبقة الخفية + طبقة المخرجات )
التعلم العميق ببساطة هو شبكة عصبية تتكون من طبقات خفية كثيرة
فرع من فروع ML تعلم الالة تتكون من خلايا عصبية اصطناعية تحاكي خلايا دماغ الانسان توجد في ٣ طبقات
(طبقة المدخلات + الطبقة الخفية + طبقة المخرجات )
التعلم العميق ببساطة هو شبكة عصبية تتكون من طبقات خفية كثيرة
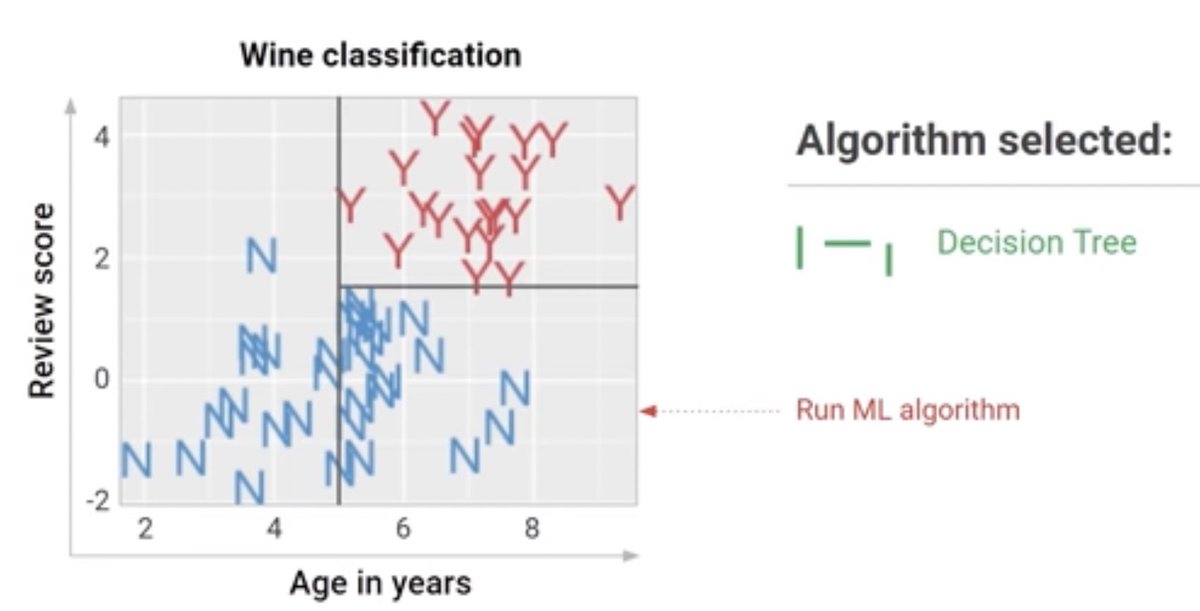
خوارزميات او ما نطلق عليه ML Models التقليدية التي تعتمد على معادلة الخط المستقيم لحل مشكلة التصنيف زي الصورة لا يعطي نتائج سليمة عند تطبيق مجموعة بيانات اخرى لاختبار المودل
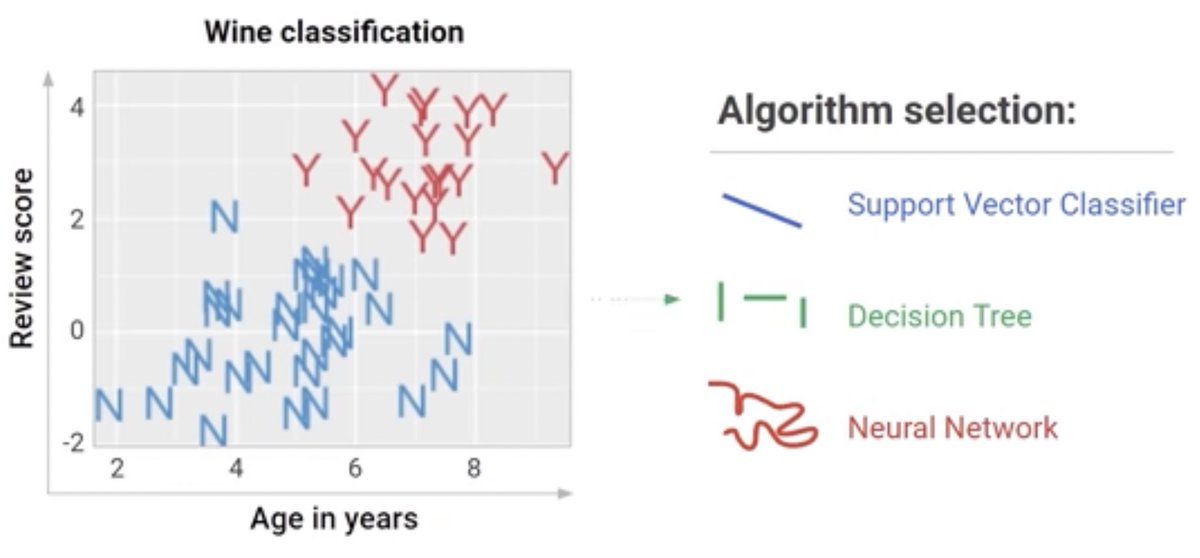
هنا ظهرت قوة الشبكات العصبية انها مرنة للغاية بحيث تستطيع رسم حدود متعرجة لحل مشكلة التصنيف وهي ناتج كل خلية عصبية في الشبكة والتي لديها القدرة لصنع القرار
مصدر الصورتين : youtu.be
مصدر الصورتين : youtu.be
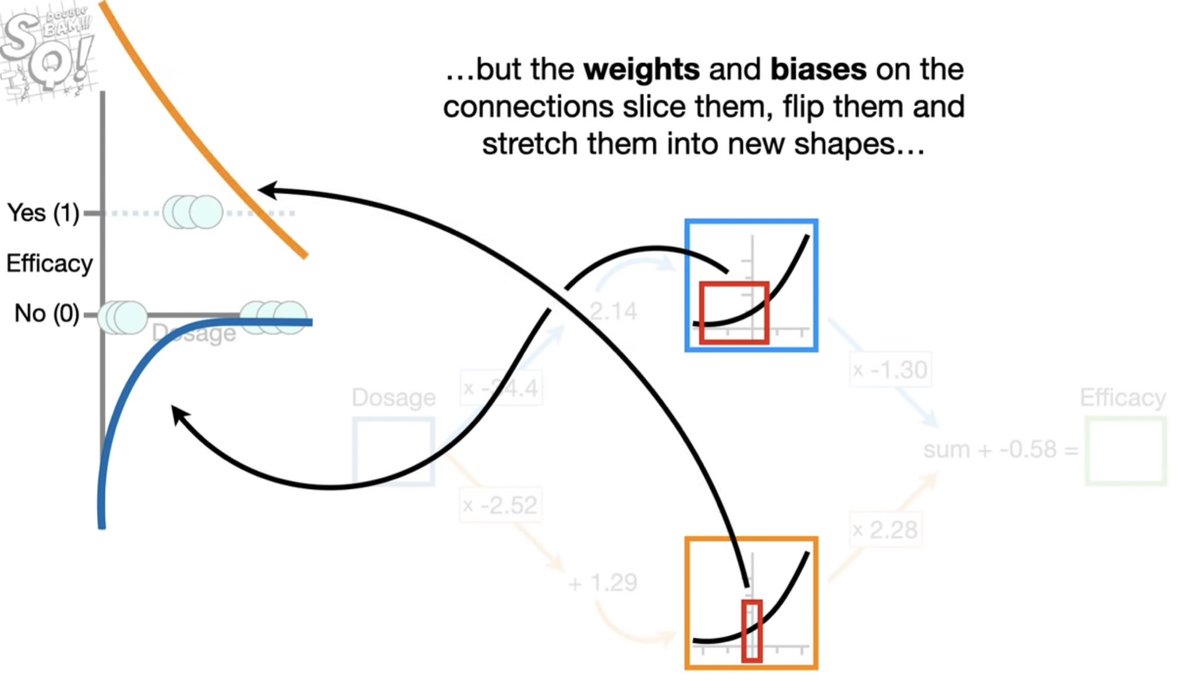
لتوضيح كيفية رسم هذي الحدود باستخدام دالة التنشيط في الخلايا العصبية والتي يطلق عليها
Activation function
ملاحظة : الشبكة العصبية تبدأ تشتغل بدالتين تنشيط متماثلتين
المصدر: youtube.com
Activation function
ملاحظة : الشبكة العصبية تبدأ تشتغل بدالتين تنشيط متماثلتين
المصدر: youtube.com
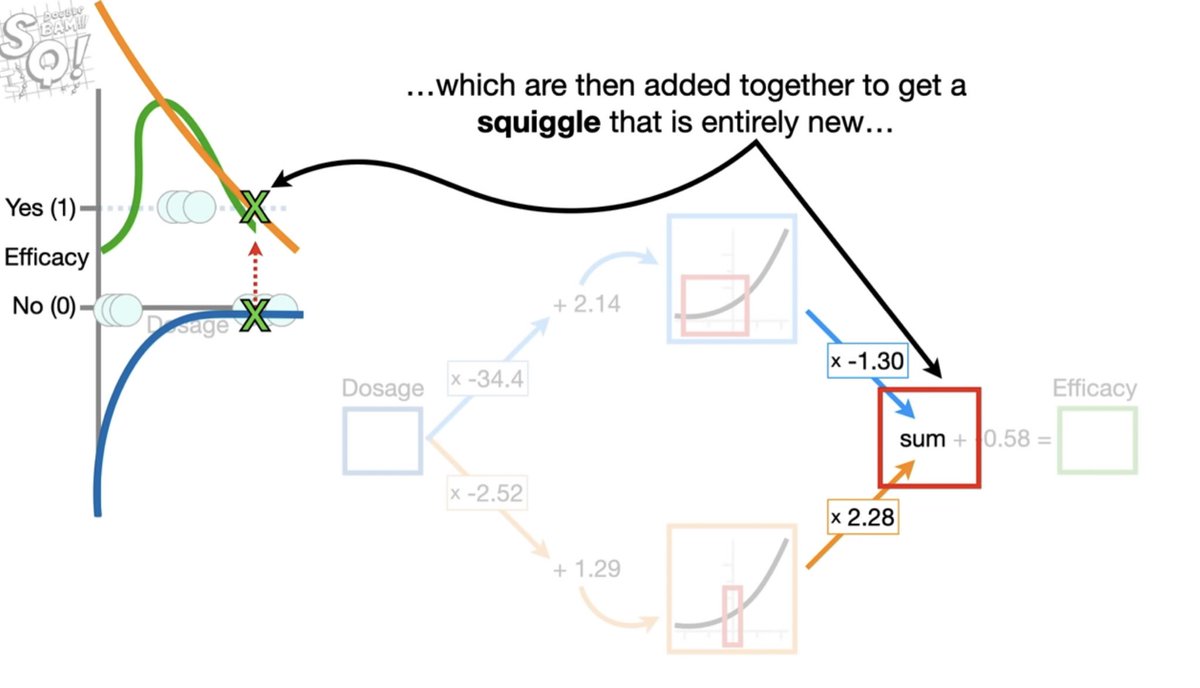

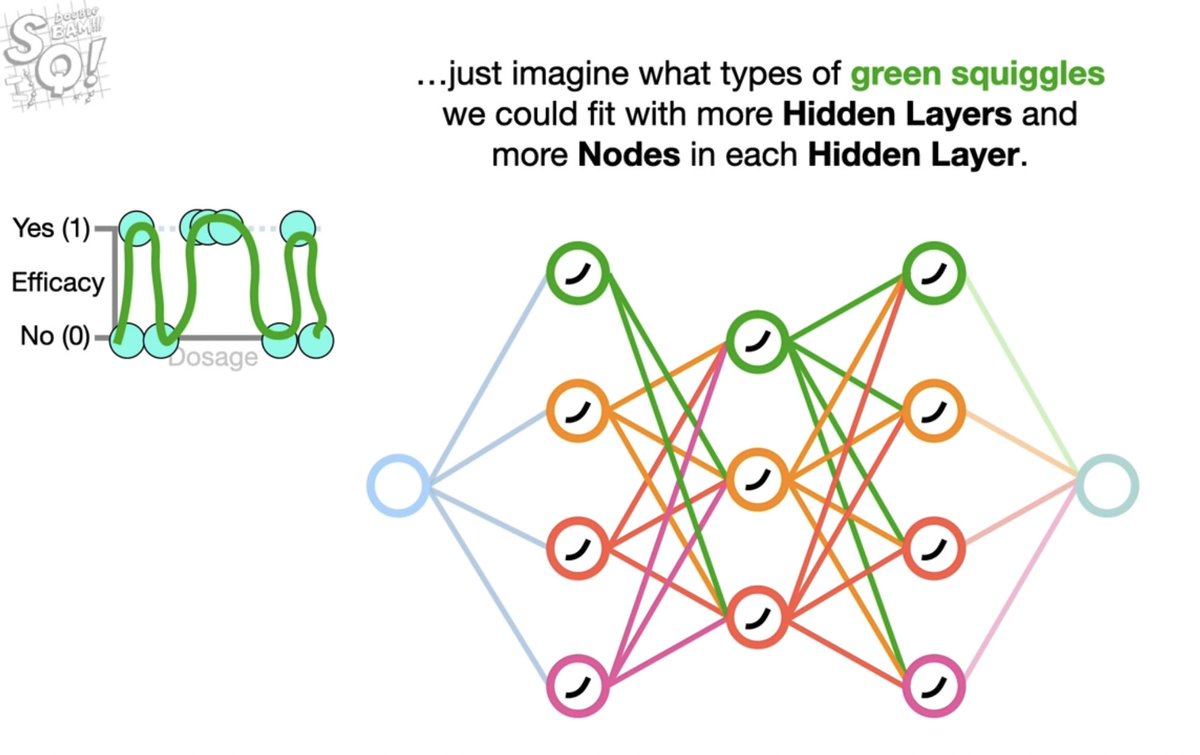
دوال التنشيط تختلف بين الطبقة الخفية وطبقة المخرجات ( عادة لا يتم الاعتراف بطبقة المدخلات لأنها لا تتكون من خلايا عصبية )
طبقة المدخلات تتكون من Features اي الخصائص فكل ما كانت هذي المدخلات لها علاقة بحل المشكلة و خالية من الاخطاء كل ماكانت عملية تعلم الشبكة سليمة والنتائج دقيقة تتصف بالعمومية generalization اي قدرة الشبكة على اعطاء نتائج جيدة من بيانات جديدة لم يراها
Feature Engineering
هو المجال او المهارة اللي الكل اتفق على تعلمها قبل برمجة الشبكة لأن اغلب الجهد يكون في معالجة البيانات تقريباً ٨٠٪ والباقي في تدريب الشبكة و تحسين ادائها
اذاً طبقة المدخلات: هي بيانات ممكن تكون ارقام / نصوص / صور / صوت
Features vs Label vs Data
هو المجال او المهارة اللي الكل اتفق على تعلمها قبل برمجة الشبكة لأن اغلب الجهد يكون في معالجة البيانات تقريباً ٨٠٪ والباقي في تدريب الشبكة و تحسين ادائها
اذاً طبقة المدخلات: هي بيانات ممكن تكون ارقام / نصوص / صور / صوت
Features vs Label vs Data
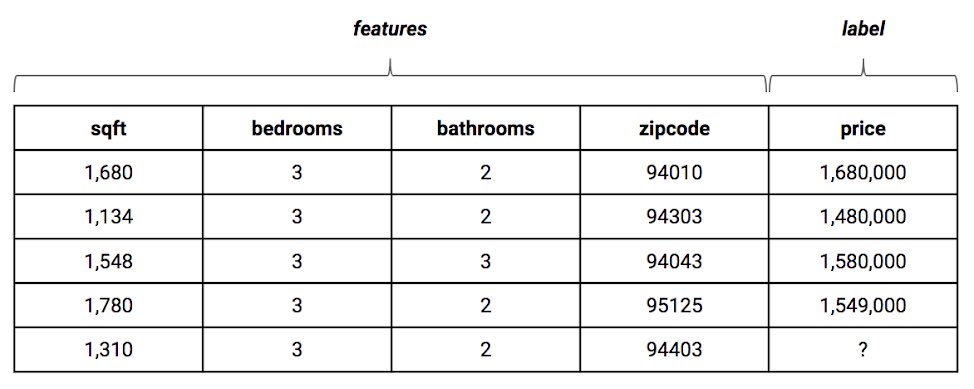
في الواقع المدخلات لا تكون دائما بطريقة منظمة في جدول اي مهيكلة مثل الصورة فوق بل العكس تماماً الصور والاصوات والنصوص تعتبر بيانات غير مهيكلة
سابقاً كان العالم يضطر الى تحويل هذي البيانات الى مهيكلة لكن قوة التعلم العميق تغلبت على هذي المشكلة في التعامل مع البيانات الغير مهيكلة
سابقاً كان العالم يضطر الى تحويل هذي البيانات الى مهيكلة لكن قوة التعلم العميق تغلبت على هذي المشكلة في التعامل مع البيانات الغير مهيكلة
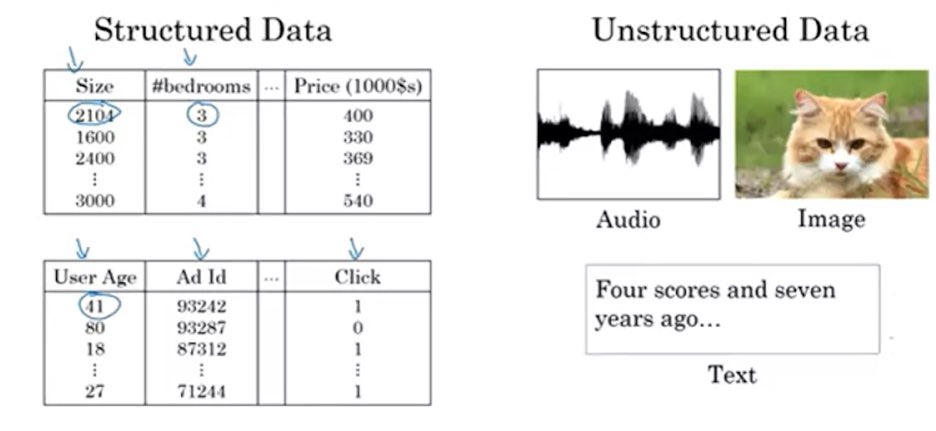
سمحت هذه القدرة للتعلم العميق في ظهور تطبيقات لم تكن موجودة من قبل
👇🏻👇🏻👇🏻
👇🏻👇🏻👇🏻

كورس ٢ /
logistic regression as neural network
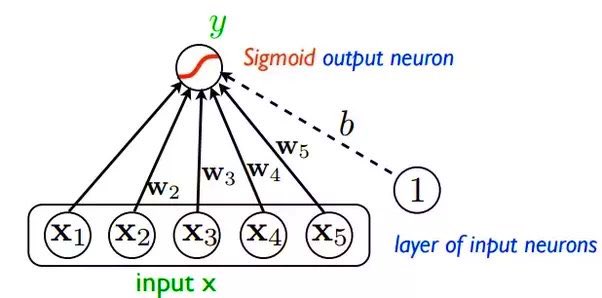
هناك جدال حول ما اذا كانت خوارزمية الانحدار اللوجستي تعتبر نوع من انواع الشبكات العصبية لأن طريقة عملها وتصميمها يشبه شبكة التغذية الامامية ذات الطبقة الواحدة اي (الخارجية) والتي تسمى Perceptron
quora.com
logistic regression as neural network
هناك جدال حول ما اذا كانت خوارزمية الانحدار اللوجستي تعتبر نوع من انواع الشبكات العصبية لأن طريقة عملها وتصميمها يشبه شبكة التغذية الامامية ذات الطبقة الواحدة اي (الخارجية) والتي تسمى Perceptron
quora.com
نقطة مهمة 📌: تعلم الالة ML ينقسم لعدة انواع من التعلم:
Supervised Learning
Unsupervised Learning
Semi-Supervised Learning
Reinforcement Learning
Supervised Learning
Unsupervised Learning
Semi-Supervised Learning
Reinforcement Learning
1- التعلم بالإشراف اي الانسان يعتبر كمشرف بمعنى تضمين الاجابة الصحيحه لكل مدخل تسمى Labels و مجموعة البيانات يطلق عليها
Labelling Datadet
تدريب الشبكة يكون قائم على إنتاج مخرجات قريبة جداً جداً الى الحقيقة عن طريق ايجاد الفرق بين المخرج الذي انتجته y_hat والمخرج الحقيقي y
Labelling Datadet
تدريب الشبكة يكون قائم على إنتاج مخرجات قريبة جداً جداً الى الحقيقة عن طريق ايجاد الفرق بين المخرج الذي انتجته y_hat والمخرج الحقيقي y
حتى تتعلم الشبكة تحتاج تغير معاملاتها ( الاوزان + التحيز ) حتى تصل الى اقل قيمة فرق بين المخرجات المنتجه والصحيحه
لذا تسمى بعملية تعلم بالاشراف
مهم نعرف انو الشبكات تعتمد على مبدأ الاحتمالات في صنع القرار فالمخرجات تكون احتمال ما مدى قرب الناتج من الحقيقة
لذا تسمى بعملية تعلم بالاشراف
مهم نعرف انو الشبكات تعتمد على مبدأ الاحتمالات في صنع القرار فالمخرجات تكون احتمال ما مدى قرب الناتج من الحقيقة
اذاً الهدف⛳️:ايجاد اقل فرق بين
الy_hat و y الحقيقة يطلق على المعادلة دالة الخطأ loss function تهتم بحساب الخطأ لكل عنصر تدريب
في حين متوسط مجموع الاخطاء لمجموعة بيانات التدريب بشكل كامل يعرف بـ cost function
السؤال كيف ممكن اغير ناتج الخلايا العصبية حتى تعطيني الناتج المطلوب ؟
الy_hat و y الحقيقة يطلق على المعادلة دالة الخطأ loss function تهتم بحساب الخطأ لكل عنصر تدريب
في حين متوسط مجموع الاخطاء لمجموعة بيانات التدريب بشكل كامل يعرف بـ cost function
السؤال كيف ممكن اغير ناتج الخلايا العصبية حتى تعطيني الناتج المطلوب ؟
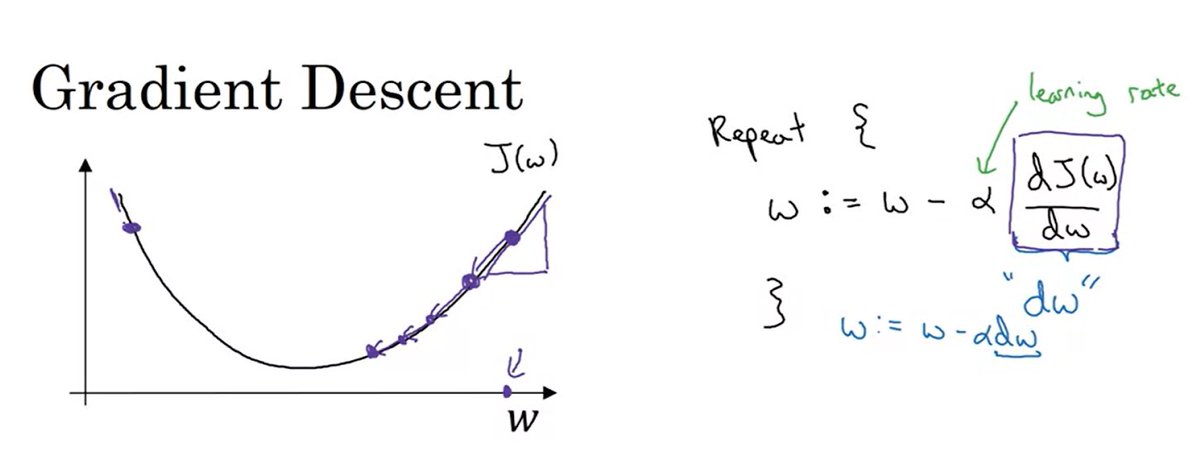
هنا يجي دور دالة التحسين Optimization function واشهرها
الانحدار التدريجي gradient descent
تهتم بتحديث ال parameters وهي
Weights & biases
باشتقاق derivatives معادلة الخطأ cost function
يمكن ان نعبر عن الاشتقاق بميل المعادلة ال slop
الانحدار التدريجي gradient descent
تهتم بتحديث ال parameters وهي
Weights & biases
باشتقاق derivatives معادلة الخطأ cost function
يمكن ان نعبر عن الاشتقاق بميل المعادلة ال slop
احد مميزات 🎖استخدام الاشتقاق في عملية الانحدار التدريجي وتحديث معاملات الشبكة انو بغض النظر عن المكان اللي تحسب منه ميل المعادلة راح يعطيك نفس الناتج اي الميل ثابت
الصورة من الكورس👇🏻
الصورة من الكورس👇🏻
هناك خطوة مهمة جداً قبل البدء بعملية التحسين بالانحدار التدريجي
تهيئة المعاملات initializing بقيم اولية اما اصفار او عشوائية Random
ماذا يحدث لما نختار قيم صفرية للأوزان ؟ راح تعطينا كل خلية في الطبقة المخفية نفس الناتج اي دوال التنشيط اصبحت متماثلة على الرغم من عدد التكرارات
تهيئة المعاملات initializing بقيم اولية اما اصفار او عشوائية Random
ماذا يحدث لما نختار قيم صفرية للأوزان ؟ راح تعطينا كل خلية في الطبقة المخفية نفس الناتج اي دوال التنشيط اصبحت متماثلة على الرغم من عدد التكرارات
اذاً الحل ✅:
اختيار التهيئة العشوائية لمعاملات الاوزان وضربها برقم صغير مثل 0.01 حتى تكون الاوزان صغيره جداً وعملية التعلم سريعه
اختيار التهيئة الصفرية لمعاملات التحيز
بعدها تبدأ خوارزمية الانحدار التدريجي من هذي النقاط الاولية ثم تتحرك في اتجاه نحو منطقة اشد انحداراً
اختيار التهيئة العشوائية لمعاملات الاوزان وضربها برقم صغير مثل 0.01 حتى تكون الاوزان صغيره جداً وعملية التعلم سريعه
اختيار التهيئة الصفرية لمعاملات التحيز
بعدها تبدأ خوارزمية الانحدار التدريجي من هذي النقاط الاولية ثم تتحرك في اتجاه نحو منطقة اشد انحداراً
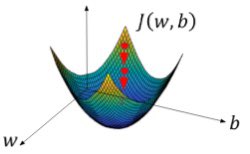
مع كل عملية تحديث للمعاملات للوصول الى افضل معامل يعطي ناتج دالة ال cost اقل قيمة ممكنة تتكون عندي حلقة تكرار
حتى يصل الى Global Optimum ( القاع)
يتحكم في حجم الخطوات هذي بين كل تكرار والثاني معامل يسمى الفا اي معدل التعلم Learning Rate
حتى يصل الى Global Optimum ( القاع)
يتحكم في حجم الخطوات هذي بين كل تكرار والثاني معامل يسمى الفا اي معدل التعلم Learning Rate
نقطة مهمة 📌: تختلف الدوال حسب نوع المشكلة اذا من المهم تحديد الدالة المناسبة ومعرفة اسمها والقراءة عنها لأن لها جوانب نقص وعيوب قد لا تساعدك في حل المشكلة لذا لكل دالة loss هناك دالة optimizer تعمل على تحسينها فالدالتين مرتبطتين ببعض
المصدر: towardsdatascience.com
المصدر: towardsdatascience.com

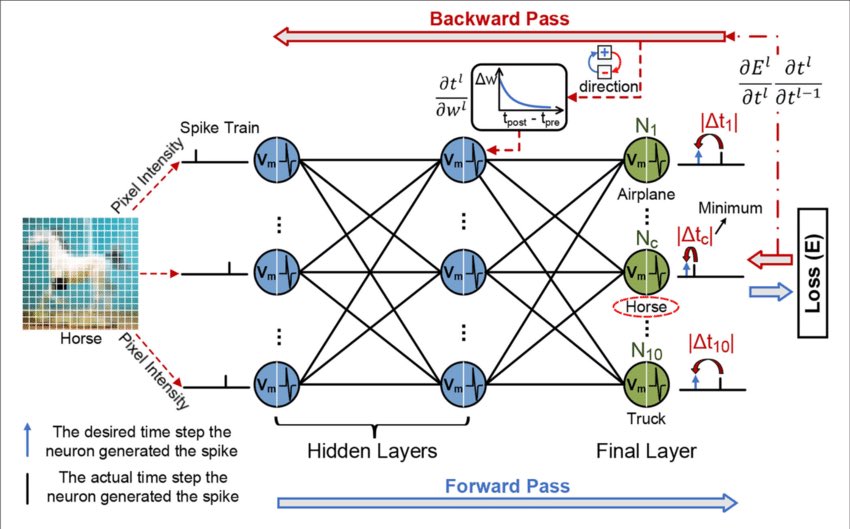
عملية دخول البيانات للشبكة وحساب ناتجها تسمى Forward propagation
وعند حساب معادلة الخطأ في الناتج الاخير للشبكة ويكون غير المطلوب تعود الشبكة من الخلف الى الامام حتى تحدث المعاملات وتنتج لنا ناتج جديد تسمى
العملية backward propagation
المصدر: researchgate.net
وعند حساب معادلة الخطأ في الناتج الاخير للشبكة ويكون غير المطلوب تعود الشبكة من الخلف الى الامام حتى تحدث المعاملات وتنتج لنا ناتج جديد تسمى
العملية backward propagation
المصدر: researchgate.net
مصادري الخاصة اللي استعنت بها خلال دراستي الكورس في الجامعة :
لفهم المعادلات الرياضية للشبكات العصبية NN
towardsdatascience.com
لفهم انواع دوال الloss والفرق بينها
wangxinliu.com
مقدمة عن NN باللغة العربية
informatic-ar.com
لفهم المعادلات الرياضية للشبكات العصبية NN
towardsdatascience.com
لفهم انواع دوال الloss والفرق بينها
wangxinliu.com
مقدمة عن NN باللغة العربية
informatic-ar.com
كتب ساعدتني 📚
١- كتاب من ٦ فصول يشرح بالامثلة ويطبقها بالبايثون 💻
neuralnetworksanddeeplearning.com
٢- كتب مراجع كورس الجامعة 🗂
هذا اضطريت اطلبه من الكاتبه وتجاوبت سريع الحمدلله
researchgate.net
والثاني كان متوفر pdf
lps.ufrj.br
١- كتاب من ٦ فصول يشرح بالامثلة ويطبقها بالبايثون 💻
neuralnetworksanddeeplearning.com
٢- كتب مراجع كورس الجامعة 🗂
هذا اضطريت اطلبه من الكاتبه وتجاوبت سريع الحمدلله
researchgate.net
والثاني كان متوفر pdf
lps.ufrj.br
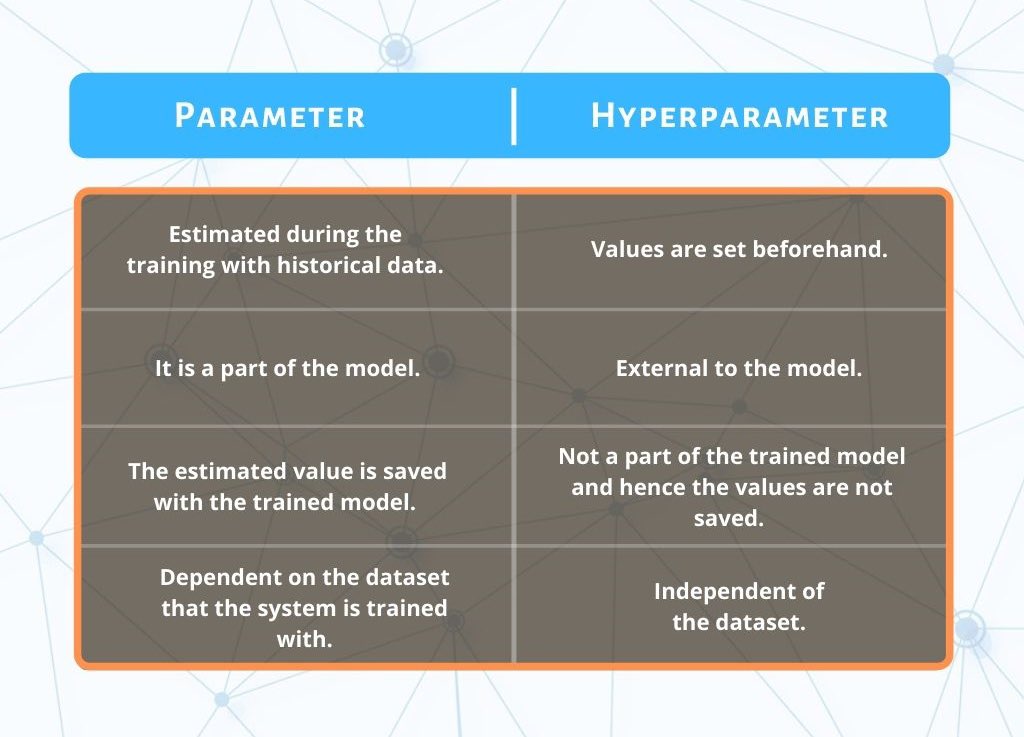
parameters
المعاملات الاساسية للشبكة وتؤثر بشكل مباشر في صنع قرار الخلايا العصبية وهي (الاوزان والتحيز )
hyperparamters
جميع المعاملات الثانوية التي تساعد في تحسين اداء المعاملات الاساسية
أمثلة:
عدد طبقات الشبكة الخفية وعدد الخلايا العصبية فيها
معدل التعلم
معامل التنظيم لامبدا
المعاملات الاساسية للشبكة وتؤثر بشكل مباشر في صنع قرار الخلايا العصبية وهي (الاوزان والتحيز )
hyperparamters
جميع المعاملات الثانوية التي تساعد في تحسين اداء المعاملات الاساسية
أمثلة:
عدد طبقات الشبكة الخفية وعدد الخلايا العصبية فيها
معدل التعلم
معامل التنظيم لامبدا
كورس ٣:
setting up your ML model
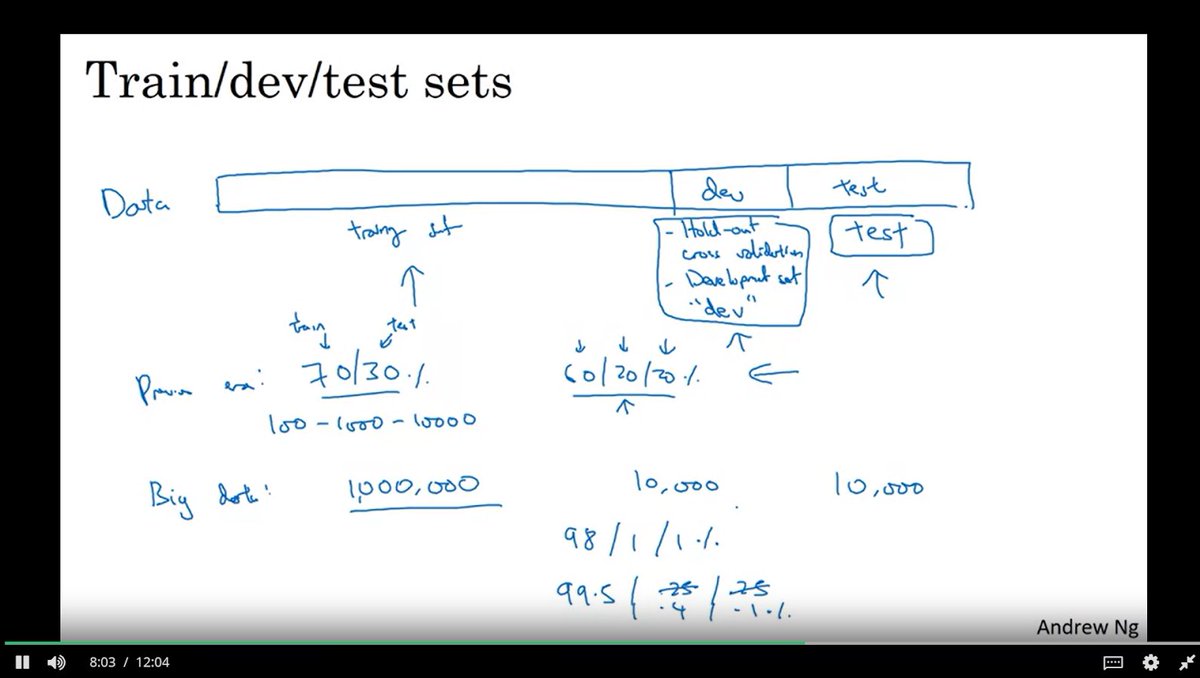
اول خطوة هي تقسيم مجموعة البيانات (Dataset) الى
Train/ Dev / Test
سابقاً كانت نسبة التقسيم بين المجموعات :
70% -30%
وعندما تتضمن مجموعة التطوير تصبح :
60% -20%-20%
النسبة الاعلى لمجموعة للتدريب
setting up your ML model
اول خطوة هي تقسيم مجموعة البيانات (Dataset) الى
Train/ Dev / Test
سابقاً كانت نسبة التقسيم بين المجموعات :
70% -30%
وعندما تتضمن مجموعة التطوير تصبح :
60% -20%-20%
النسبة الاعلى لمجموعة للتدريب
لكن مع ظهور البيانات الضخمة Big data تغيرت الحسبة الى :
98% - 1% - 1% or
99.5% - 0.4% - 0.1%
98% - 1% - 1% or
99.5% - 0.4% - 0.1%
نقاط مهمة في توزيع البيانات 📌
١-الاكتفاء ببيانات Train and Dev قد يسبب overfitting في dev set اذا نحتاج لبيانات اختبار
٢-زيادة عدد بيانات مجموعة الاختبار دون زيادتها في التطوير يضر في نتائج المودل لأن اصبح لهم توزيع مختلف ( ومهمة هذي النقطه ضروري يكون لهم نفس التوزيع )
١-الاكتفاء ببيانات Train and Dev قد يسبب overfitting في dev set اذا نحتاج لبيانات اختبار
٢-زيادة عدد بيانات مجموعة الاختبار دون زيادتها في التطوير يضر في نتائج المودل لأن اصبح لهم توزيع مختلف ( ومهمة هذي النقطه ضروري يكون لهم نفس التوزيع )
كورس ٢/ Bias and Variance
طيب متى نعرف انو حصل عندنا تباين او تحيز ؟
نراقب ال error or loss بين مرحلتين
( التدريب والتطوير ) او ( التدريب و الاختبار ) حسب تقسيم البيانات المستخدم
عندنا ٤ حالات وهي :
طيب متى نعرف انو حصل عندنا تباين او تحيز ؟
نراقب ال error or loss بين مرحلتين
( التدريب والتطوير ) او ( التدريب و الاختبار ) حسب تقسيم البيانات المستخدم
عندنا ٤ حالات وهي :
١- تباين عالي 🎢 : الخطأ صغير جداً في Train set وكبير جداً في Dev Test
يعني المودل نجح في التعرف بدقة على التدريب وفشل في المجموعة التي لم يراها
تسمى هذي الحالة ( overfitting )
يعني المودل نجح في التعرف بدقة على التدريب وفشل في المجموعة التي لم يراها
تسمى هذي الحالة ( overfitting )
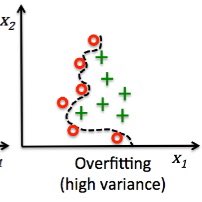
٢- تحيز عالي : الخطأ عالي في المجموعتين و متقارب جداً جداً
اي ان المودل فشل في التعرف عليهم الاثنين
نطلق على هذا الحالة مسمى ( underfitting )
اي ان المودل فشل في التعرف عليهم الاثنين
نطلق على هذا الحالة مسمى ( underfitting )

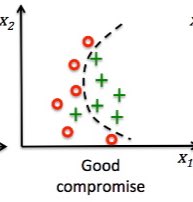
٣- تحيز و تباين منخفضين :
الخطأ منخفض في الاثنين و متقاربين ( الافضل )
الخطأ منخفض في الاثنين و متقاربين ( الافضل )
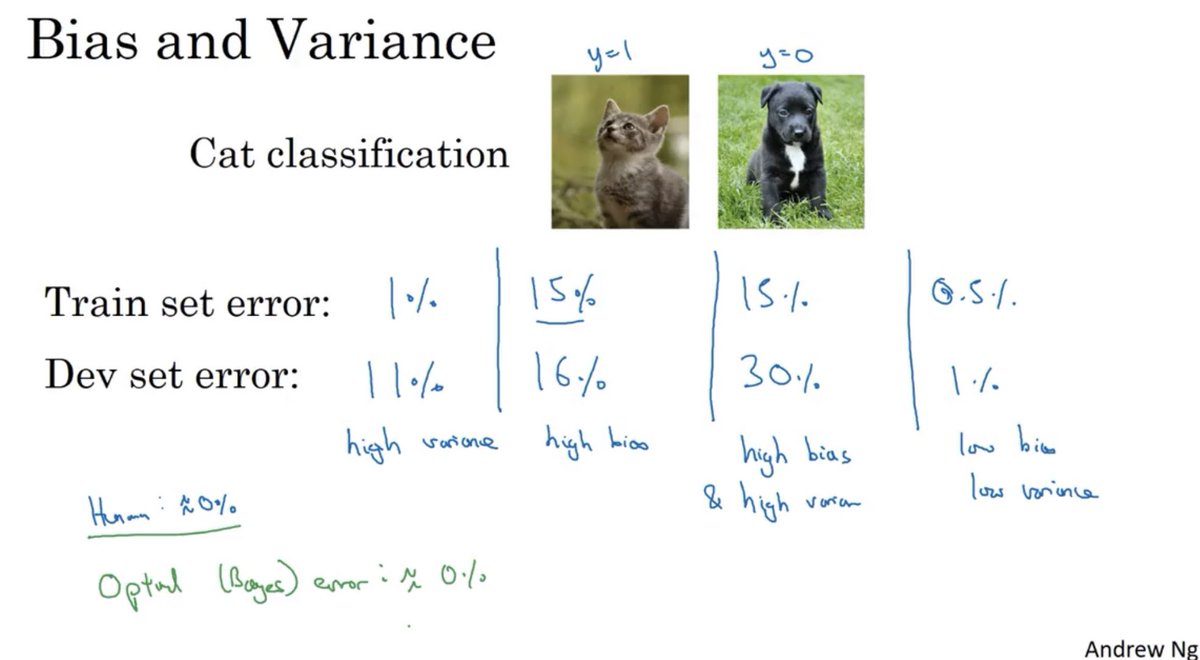
٤- تحيز و تباين عاليان : معدل خطأ عالي للمجموعتين ولكن في مجموعة التطوير اعلى ( اسوء الحالات )
مثال بالأرقام كما تم شرحه في الكورس
طيب كيف نحاول نوصل المودل من الحالات هذي الى الحالة الافضل ؟
في البداية نسأل انفسنا اذا عندنا تحيز عالي او لا .. اي ان المشكلة في Train set
نجرب هذه الحلول المقترحة :
١- نكبر الشبكة اي نزيد عدد الطبقات الخفية او عدد الخلايا العصبية في الطبقات الخفية
في البداية نسأل انفسنا اذا عندنا تحيز عالي او لا .. اي ان المشكلة في Train set
نجرب هذه الحلول المقترحة :
١- نكبر الشبكة اي نزيد عدد الطبقات الخفية او عدد الخلايا العصبية في الطبقات الخفية
تابع ^
٢- اذا كانت الشبكة كبيرة نجرب نزيد مدة تدريب المودل number of epoch
٣- اخر الحلول ( ممكن يعمل وممكن لا ) نجرب هيكلة شبكة جديدة ومختلفة
٢- اذا كانت الشبكة كبيرة نجرب نزيد مدة تدريب المودل number of epoch
٣- اخر الحلول ( ممكن يعمل وممكن لا ) نجرب هيكلة شبكة جديدة ومختلفة
بعد ما نتأكد انو ماعندنا تحيز عالي نسأل اذا تباين عالي يعني المشكلة في مجموعة التطوير Dev
الحلول المقترحة :
١- نجرب اول شيء نزيد عدد البيانات في المجموعة
٢- اذا ما نفع نستخدم التنظيم Regularization
٣- اخر الحلول نجرب هيكلة شبكة مختلفة
هذي الحلول المقترحة بشكل عام
الحلول المقترحة :
١- نجرب اول شيء نزيد عدد البيانات في المجموعة
٢- اذا ما نفع نستخدم التنظيم Regularization
٣- اخر الحلول نجرب هيكلة شبكة مختلفة
هذي الحلول المقترحة بشكل عام

سابقاً مصطلح الـ
Trade-off bias/ Variance كان مشهور في عالم ML
وهو يتكلم عن اهمية المقاضاة بين التحيز و التباين اي نقلل واحد منهم في حين يضر الطرف الثاني بالزيادة
Trade-off bias/ Variance كان مشهور في عالم ML
وهو يتكلم عن اهمية المقاضاة بين التحيز و التباين اي نقلل واحد منهم في حين يضر الطرف الثاني بالزيادة
لكن الان في عصر التعلم العميق والبيانات الضخمة طالما يمكنك
١- تدريب شبكة كبيرة لتقلل التحيز
٢- والحصول على المزيد من البيانات او القيام بتنظيم الشبكة بشكل جيد لتقلل التابين دون الضرر بالتحيز
فلن تحتاج لهذا المصطلح بعد اليوم
١- تدريب شبكة كبيرة لتقلل التحيز
٢- والحصول على المزيد من البيانات او القيام بتنظيم الشبكة بشكل جيد لتقلل التابين دون الضرر بالتحيز
فلن تحتاج لهذا المصطلح بعد اليوم
جاري تحميل الاقتراحات...