

1️⃣ كباحث حديث في مجال معالجة اللغات الطبيعية Natrual Language Processing (NLP) ومن خلال حصيلة علمية جنيتها من خلال البحث والقراءة في العديد من المصادر خلال الشهور القليل الماضية، لذلك في هذا الثريد سوف اقدم ملخص ونقطة انطلاق للمهتمين والذين لديهم رغبة في التعرف على هذا المجال
2️⃣ Natural Language Processing (NLP):
ببساطة هي عملية معالجة لغة البشر سواء كانت نصوص أو اصوات أو تعليقات لهدف تمكين الحاسب على فهمها واستيعاب محتواها.
وذلك لان الحاسب فقط لديه القدرة على فهم لغة الأرقام [01] ولا يستطيع استيعاب لغة البشر باشكالها المختلفة وعلى هيئتها الخام.
ببساطة هي عملية معالجة لغة البشر سواء كانت نصوص أو اصوات أو تعليقات لهدف تمكين الحاسب على فهمها واستيعاب محتواها.
وذلك لان الحاسب فقط لديه القدرة على فهم لغة الأرقام [01] ولا يستطيع استيعاب لغة البشر باشكالها المختلفة وعلى هيئتها الخام.
3️⃣ لذلك يهتم علم NLP على تفسير لغة البشر للحاسب وتحويلها الى هيئة ارقام او متغيرات لكي يستطيع فهمها، ومعالجتها على النحو المطلوب.
وسوف اسرد مراحل عملية المعالجة باختصار وبشكل مبسط:
وسوف اسرد مراحل عملية المعالجة باختصار وبشكل مبسط:
4️⃣ المرحلة المبدئية:
تجهيز وتنظيف البيانات النصية (Data Processing):
ويتم خلال عدة مراحل:
📎 حذف الرموز والايميلات والروابط و الاشكال والمسافات المكررة من النص مثل (@&$€#*+) ويتم من خلال استخدام Regular Expression
وممكن وتجربتها بشكل عملي من خلال الرابط:
regexr.com
تجهيز وتنظيف البيانات النصية (Data Processing):
ويتم خلال عدة مراحل:
📎 حذف الرموز والايميلات والروابط و الاشكال والمسافات المكررة من النص مثل (@&$€#*+) ويتم من خلال استخدام Regular Expression
وممكن وتجربتها بشكل عملي من خلال الرابط:
regexr.com
5️⃣ 📎 Stemming & Lemmatization:
Stemming هو اعادة الكلمة لأصلها او جذعها مثلاً كلمة (Playing) يتم اعادتها لجذعها الأساسي (play) ، بينما يستخدم lemmatization السياق الذي يتم استخدام الكلمة فيه والاخذ في الاعتبار التحليل الصرفي مثلا فعل أو أسم.
Stemming هو اعادة الكلمة لأصلها او جذعها مثلاً كلمة (Playing) يتم اعادتها لجذعها الأساسي (play) ، بينما يستخدم lemmatization السياق الذي يتم استخدام الكلمة فيه والاخذ في الاعتبار التحليل الصرفي مثلا فعل أو أسم.
6️⃣ 📎 Stop Words:
حذف كلمات التوقف وهو حذف الكلمات التي لا تغير من معنى النص مثلا (and, if, of, for) وباللغة العربية مثل (في، مهما، اولئك) لسببين:
١/حذف الكلمات المكررة والتي لا تؤثر على المعنى في النص ليسهل على المودل عملية التصنيف أو التنبؤ.
٢/التقليل من حجم البيانات.
حذف كلمات التوقف وهو حذف الكلمات التي لا تغير من معنى النص مثلا (and, if, of, for) وباللغة العربية مثل (في، مهما، اولئك) لسببين:
١/حذف الكلمات المكررة والتي لا تؤثر على المعنى في النص ليسهل على المودل عملية التصنيف أو التنبؤ.
٢/التقليل من حجم البيانات.

7️⃣ 📎Tokenization:
ببساطة فصل الكلمات في النص لتصبح كلمات متفرقة او مصفوفة مثلا
("My Son like playing football")
تحول إلى:
[“my”, “son”, “like”, “playing,” “ football”]
وهنالك مودل تدعم اللغة العربية ولديها قدرة جيدة في فصل الكلمات حتى المكونة من جزئين مثل مكة المكرمة،أبو ظبي
ببساطة فصل الكلمات في النص لتصبح كلمات متفرقة او مصفوفة مثلا
("My Son like playing football")
تحول إلى:
[“my”, “son”, “like”, “playing,” “ football”]
وهنالك مودل تدعم اللغة العربية ولديها قدرة جيدة في فصل الكلمات حتى المكونة من جزئين مثل مكة المكرمة،أبو ظبي

8️⃣🛑 وبعد تجهيز البيانات وتنظيفها نقوم بتحويل النصوص الى أرقام او متغيرات التي يتم اجراءها تحت العملية التالية:
🔸Word Embedding & Word Vector:
تعد أهم عملية وهي تمثيل الكلمات والنصوص الى ارقام او متغيرات واعطاء كل كلمة وزن بهدف ربط الكلمات متشابهة المعنى والقريبة من بعضها.
🔸Word Embedding & Word Vector:
تعد أهم عملية وهي تمثيل الكلمات والنصوص الى ارقام او متغيرات واعطاء كل كلمة وزن بهدف ربط الكلمات متشابهة المعنى والقريبة من بعضها.
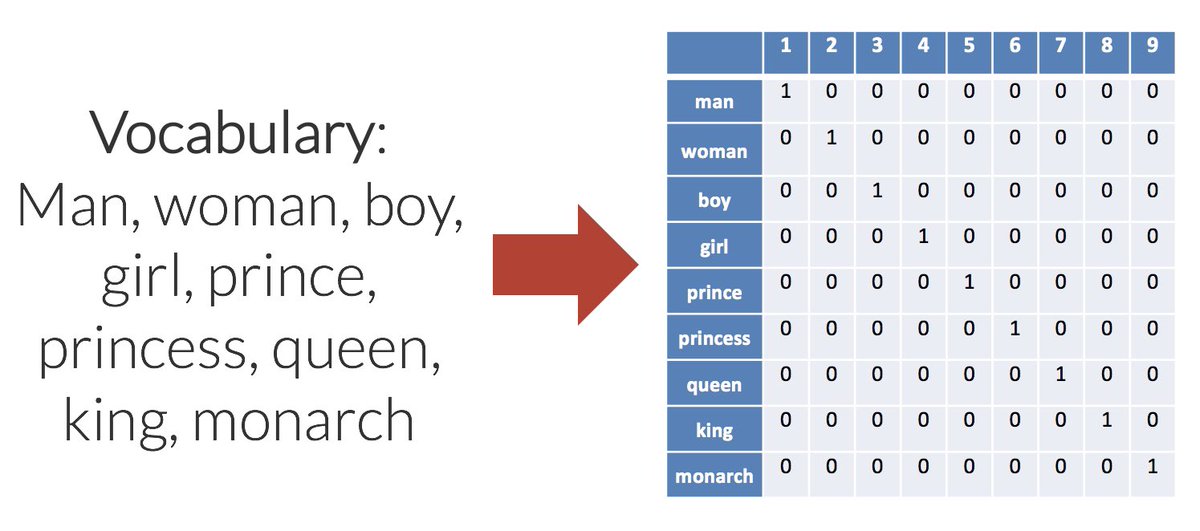
9️⃣ على سبيل المثال البشر قادرين على معرفة أن (King) رجل وأن (Queen) امراة ولكن الحاسب ليس لديه قدرة البشر في التمييز بينهم ولكن يمكن ان يتم تدريبه من خلال عمليات حسابية
(king - men = queen)
وتوجد عدة خوارزميات تقوم بهذه الوظيفة سوف نستعرض بعضها ونعرض أهم مزايا وعيوب كل منها
(king - men = queen)
وتوجد عدة خوارزميات تقوم بهذه الوظيفة سوف نستعرض بعضها ونعرض أهم مزايا وعيوب كل منها

🔟 ◾️TF-IDF:
وهي خوارزمية تقوم على تمثيل النصوص في المستند بأرقام (متغير) وذلك من خلال اعطاء وزن لكل كلمة في النص وكلما تكررت الكلمة داخل المستند وفي أكثر من نص قل وزنها وتقل قيمتها بدون اي مراعاة لترتيب الكلمات أو مكانها او ترتيبها التسلسلي في النص.
وهي خوارزمية تقوم على تمثيل النصوص في المستند بأرقام (متغير) وذلك من خلال اعطاء وزن لكل كلمة في النص وكلما تكررت الكلمة داخل المستند وفي أكثر من نص قل وزنها وتقل قيمتها بدون اي مراعاة لترتيب الكلمات أو مكانها او ترتيبها التسلسلي في النص.

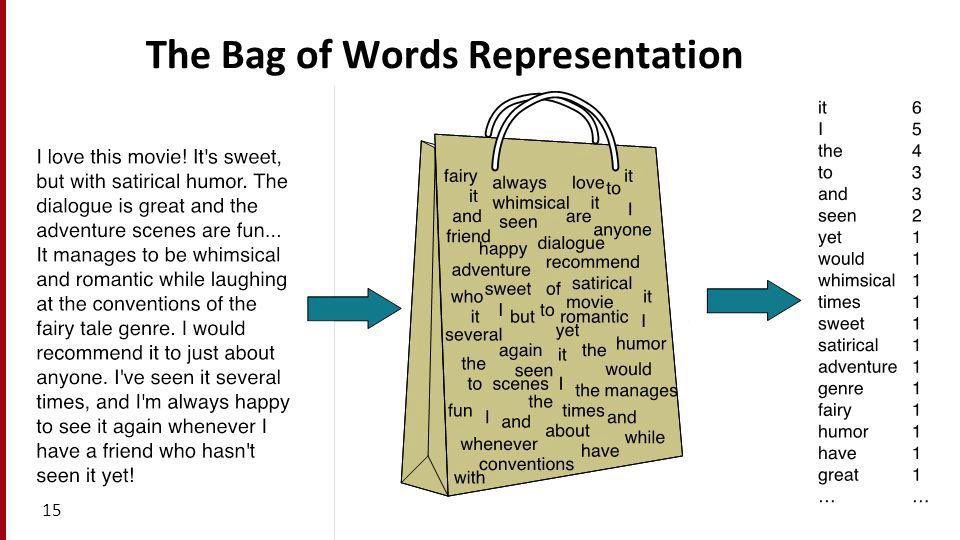
1️⃣1️⃣◾️BOW:
مودل حقيبة الكلمات (Bag of Word) يتم تمثيل النص (مثل جملة أو مستند) كحقيبة لكل الكلمات التي وردت في النص، متجاهلاً القواعد النحوية وحتى ترتيب الكلمات مع الحفاظ على التعددية ويزداد وزن كل كلمة تكررت في النص.
مودل حقيبة الكلمات (Bag of Word) يتم تمثيل النص (مثل جملة أو مستند) كحقيبة لكل الكلمات التي وردت في النص، متجاهلاً القواعد النحوية وحتى ترتيب الكلمات مع الحفاظ على التعددية ويزداد وزن كل كلمة تكررت في النص.
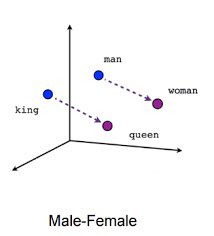
1️⃣2️⃣◾️Word2vec:
هي خوارزمية اصدرتها Google في 2013 تستخدم نموذج الشبكة العصبية لتمثيل النصوص بمتغيرات لتعلم ارتباطات الكلمات من مجموعة كبيرة من النصوص. بمجرد التدريب ، يمكن لمثل هذا النموذج اكتشاف الكلمات المترادفة واقتراح كلمات إضافية وتتم مراعاة ترتيب الكلمات في اتجاه واحد.
هي خوارزمية اصدرتها Google في 2013 تستخدم نموذج الشبكة العصبية لتمثيل النصوص بمتغيرات لتعلم ارتباطات الكلمات من مجموعة كبيرة من النصوص. بمجرد التدريب ، يمكن لمثل هذا النموذج اكتشاف الكلمات المترادفة واقتراح كلمات إضافية وتتم مراعاة ترتيب الكلمات في اتجاه واحد.
1️⃣3️⃣◾️BERT:
خوارزمية اصدرتها Google عام 2018 وتعد واحد من اقوى واحدث المودل في لمثيل النصوص ولديها القدرة على استيعاب لغة البشر بشكل كبير، ويميزها انها مدربة بشكل مسبق وتستخدمها حاليا محركات بحث Google في فهم عمليات البحث بشكل افضل.
خوارزمية اصدرتها Google عام 2018 وتعد واحد من اقوى واحدث المودل في لمثيل النصوص ولديها القدرة على استيعاب لغة البشر بشكل كبير، ويميزها انها مدربة بشكل مسبق وتستخدمها حاليا محركات بحث Google في فهم عمليات البحث بشكل افضل.

1️⃣4️⃣ على سبيل المثال عندما نبحث من خلال محرك Google عن النادي الأهلي تظهر نتائج مرتبطة بعملية البحث، وهذا يحدث بفضل BERT فهي تقوم بربط الكلمات المتشابهة والقريبة من بعضها البعض وذلك من خلال تدريبها بشكل مسبق على عدد كبير من النصوص الضخمة من موقع Wikipedia
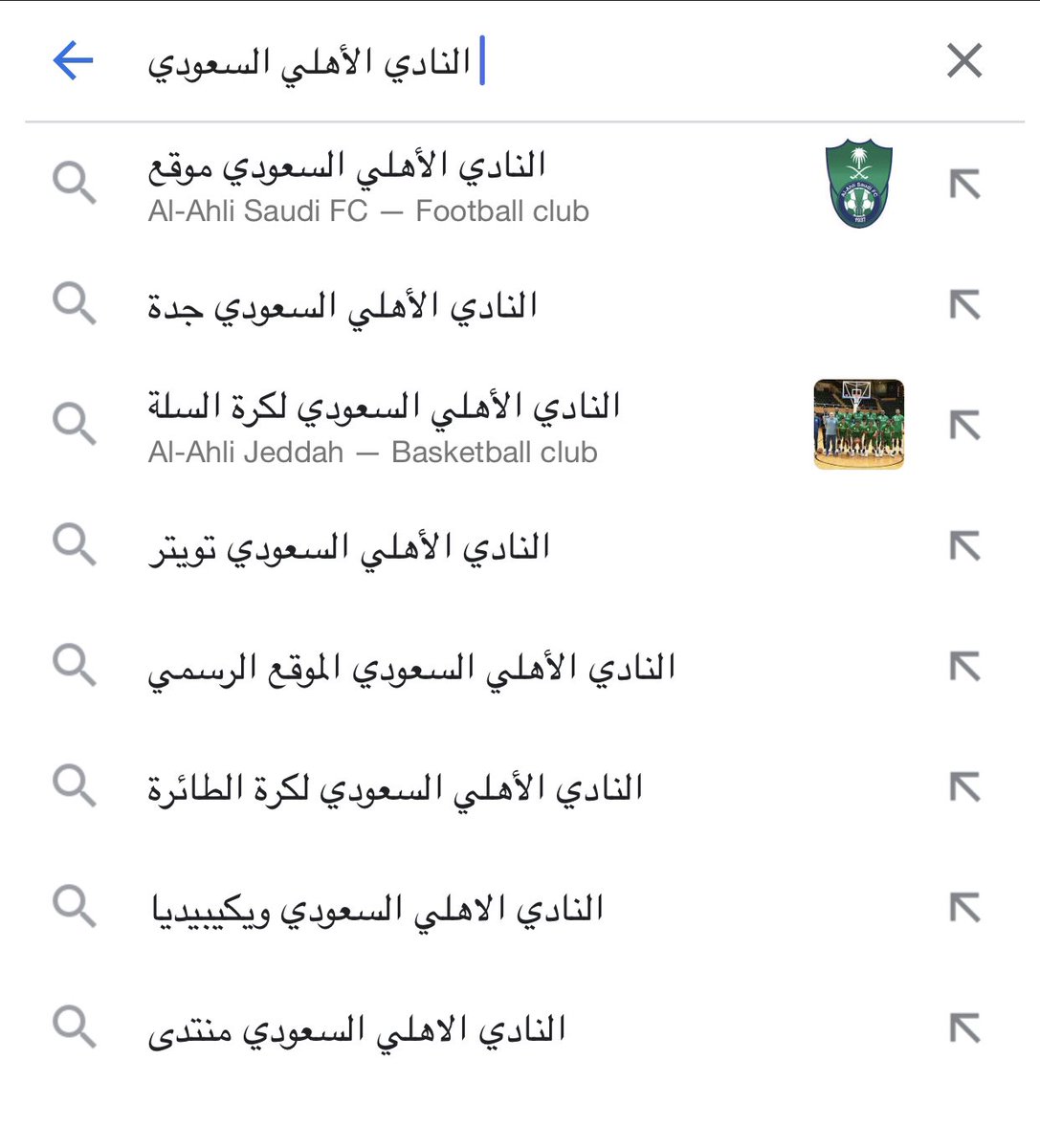
1️⃣5️⃣ وتدعم BERT اكثر من 75 لغة. كما هي تعد open source اي يمكن التعديل عليها بما يتناسب مع المشكلة او المشروع.
1️⃣6️⃣ وبعد الانتهاء من العمليات السابقة تكون البيانات جاهزة لاستخدامها وتطبيق احد الخوارزميات سواءاً لإجراء عمليات لتصنيف للبيانات او التنبؤ باستخدام احد الخوارزميات مثل Neural Networks, naive base, Logistic regression
1️⃣7️⃣ في الختام أرجو أن أكون قد وفقت في تقديم نبذة مختصرة عن NLP للمهتمين بهذا المجال، وكما أرجو أنني وفقت في ترتيب الأفكار بما يتناسب مع المساحة المحددة في Twitter، وتجدون ادناه بعض المراجع المفيدة والتي بنيت هذا الثريد من خلالها
1️⃣8️⃣ المراجع:
-1- مقدمة عن NLP
raw.githubusercontent.com
-2- مجموعة من الأوراق العلمية الشاملة عن NLP:
web.stanford.edu
-3- محرك للأبحاث العلمية في مجال NLP:
aclweb.org
-1- مقدمة عن NLP
raw.githubusercontent.com
-2- مجموعة من الأوراق العلمية الشاملة عن NLP:
web.stanford.edu
-3- محرك للأبحاث العلمية في مجال NLP:
aclweb.org

جاري تحميل الاقتراحات...