

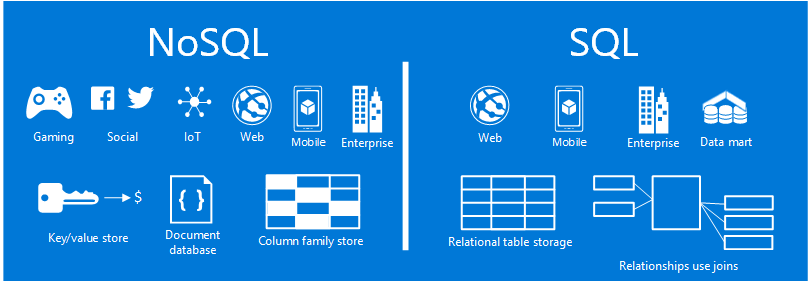
هتكلم في الثريد ده او هركز على نوع من انواع قواعد البيانات المستخدمة في عدد كبير من الProduction Systems وهي ال NoSQL Databases او ال Non-Relational Databases.
مؤخرًا بقى فيه Startups بتظهر مهمتها انها لو انتَ عايز أكلة معينة، هي بتجيبلك كل ال ingredients في بوكس وتوصله للبيت.
مؤخرًا بقى فيه Startups بتظهر مهمتها انها لو انتَ عايز أكلة معينة، هي بتجيبلك كل ال ingredients في بوكس وتوصله للبيت.
انت بتفتح البوكس تلاقي انواع مختلفة من بروتين وكاربس وبهارات في بوكس واحد، وده بيسهل ويسرع عليك جدًا انك تطلع الحاجة ديه وتصنع وجبتك على طول.
في المقابل لو هتنزل انتَ تعمل الشوبينج ده، هتروح للمكان اللي فيه كل بروتين تختار اللي محتاجه، والمكان كل البهارات تجيب اللي محتاجه وهكذا.
في المقابل لو هتنزل انتَ تعمل الشوبينج ده، هتروح للمكان اللي فيه كل بروتين تختار اللي محتاجه، والمكان كل البهارات تجيب اللي محتاجه وهكذا.
نظريًا في الحالتين هتوصل لنفس النتيجة.
بإعتبار انك عندك الف بوكس من بتوع الستارت ابس، واكتشفت ان شوية منهم فيهم بهارات بايظة، هيبقى الموضوع سخيف انك تفتح كل بوكس وتدور فيه البهارات ديه ولا لأ، ولو فيه تغيرها.
عكس لو في سوبرماركت، هتبدل رف البهارات البايظة بجديدة وخلاص.
بإعتبار انك عندك الف بوكس من بتوع الستارت ابس، واكتشفت ان شوية منهم فيهم بهارات بايظة، هيبقى الموضوع سخيف انك تفتح كل بوكس وتدور فيه البهارات ديه ولا لأ، ولو فيه تغيرها.
عكس لو في سوبرماركت، هتبدل رف البهارات البايظة بجديدة وخلاص.
رغم سطحية التشبيه الا ان جزء كبير في الفرق والـ ليه بنستعمل حاجة عن التانية عبارة عن اللي فوق.
الـ NoSQL DB بتديك سهولة انك تحتفظ بأي نوع بيانات انت عايزها من غير اي constraints في مكان واحد، بالتالي بتبقى من مناسبة جدًا للبيانات غير المرتبة اللي انت مش عارف ممكن يتضاف عليها ايه.
الـ NoSQL DB بتديك سهولة انك تحتفظ بأي نوع بيانات انت عايزها من غير اي constraints في مكان واحد، بالتالي بتبقى من مناسبة جدًا للبيانات غير المرتبة اللي انت مش عارف ممكن يتضاف عليها ايه.
عكس ال SQL اللي كل البيانات لازم تكون منظمة، ومخططة، لازم تكون عارف ال columns بتاعتك، كل سطر بيانات لازم يكون في ال columns ديه حتى لو فيه column منهم قيمته غير موجودة وهكذا.
فكرة ان قاعدة البيانات تكون غير منظمة خلى فيه انواع كتير منها، كل نوع بيحل مشكلة معينة.
فكرة ان قاعدة البيانات تكون غير منظمة خلى فيه انواع كتير منها، كل نوع بيحل مشكلة معينة.
النوع الأول هو ال Key-Value stores، ديه شبيها بالdata structure الشهيرة ال Hash، وبيبقى عندها نفس مميزتها حيث ان ال Lookup time سريع جدًا. بيتم استعمالها معظم الأحيان عشان نسجل ال User sessions في الأنظمة، بحيث نبقى عارفين مين ال users اللي فاتحين دلوقتي، بيعملوا ايه، الثيم
اللي مختارينه، وهكذا. في المثل ده ال Key مثلا بيبقى ال Unique ID بتاع المستخدم، وال Value بتبقى التفضيلات او افعال المستخدم.
من اشهر ال Databases اللي بتستخدم بقوة لحل النوعية ديه من المسائل هي Redis.
تاني نوع ال Document Databases، انتَ بتحط كل البيانات اللي عندك لـ حاجة في
من اشهر ال Databases اللي بتستخدم بقوة لحل النوعية ديه من المسائل هي Redis.
تاني نوع ال Document Databases، انتَ بتحط كل البيانات اللي عندك لـ حاجة في
دوكمنت، مثلًا عندك دوكمنت لليوزر الفولاني، هيبقى فيه كل حاجة عنه، كل البوستات اللي عملها لايك، كل التويتات، كل الصور، كله في دوكمنت واحد. وهيبقى فيه Collection بتضم ال documents اللي من نوع واحد. في المثل ده هيبقى فيه Users Collection وال documents من جواها مش ضروري يبقى فيها نفس
البيانات حتى، ممكن مستخدمين يكون عندهم بيانات مش عند التانيين وهكذا.
الداتا بيز ديه بتبقى كويسة جدًا في تطبيقات ال Content Management او البلوجات او السوشيال ميديا.
من اشهر قواعد البيانات اللي بتحل المشكلة ديه MongoDB و CouchDB
الداتا بيز ديه بتبقى كويسة جدًا في تطبيقات ال Content Management او البلوجات او السوشيال ميديا.
من اشهر قواعد البيانات اللي بتحل المشكلة ديه MongoDB و CouchDB
النوع التالت اسمه Column stores،
هنا محتاج ارجع تاني لل SQL، ازاي ال data بيتم حفظها في ال Relational DB بإختصار؟ بيبقى فيه table، ال table ده عبارة عن شوية rows، كل row بيتكون من شوية columns. ال table ده بشكل ما بيتحط في Disk. ال Column Stores بتعكس العملية ديه وبتحتفظ
هنا محتاج ارجع تاني لل SQL، ازاي ال data بيتم حفظها في ال Relational DB بإختصار؟ بيبقى فيه table، ال table ده عبارة عن شوية rows، كل row بيتكون من شوية columns. ال table ده بشكل ما بيتحط في Disk. ال Column Stores بتعكس العملية ديه وبتحتفظ
بالبيانات ك Columns، وكل مجموعة Columns مرتبطة بيتحطوا قريب من بعد ع الديسك.
طب كدة بيفرق ف ايه؟ بيفرق في قرائة البيانات ديه. في ال SQL دايمًا البيانات بتتقري من الشمال لليمين، ف لو عندك مثلًا table دوري فيه ١٠٠ column، وحبيت تجيب البيانات ال columns ديه (اسم الفريق-اسم الحارس)
طب كدة بيفرق ف ايه؟ بيفرق في قرائة البيانات ديه. في ال SQL دايمًا البيانات بتتقري من الشمال لليمين، ف لو عندك مثلًا table دوري فيه ١٠٠ column، وحبيت تجيب البيانات ال columns ديه (اسم الفريق-اسم الحارس)
وكان عندك مليون فريق، هو هيلف على ال 100 column في المليون فريق وياخد منهم الاتنين columns اللي انت طالبهم بس.
ال Column Stores بتلف على Columns الحارس و اسم الفريق بس، وبتتبع طرق Optimizations كمان فيها بتخليها اسرع. وبما ان ال columns مختلفة، ف مش هيبقى فيه مشكلة ان لما تحب
ال Column Stores بتلف على Columns الحارس و اسم الفريق بس، وبتتبع طرق Optimizations كمان فيها بتخليها اسرع. وبما ان ال columns مختلفة، ف مش هيبقى فيه مشكلة ان لما تحب
تـ Scale تحط شوية columns في server تاني، بالتالي هي Horizontally Scalable. وبما انها قريبة من ال SQL ف هي قادرة تستعمل Syntax قريب من ال SQL وده بيسرع الدنيا في التطوير حيث ان ال SQL كل المبرمجين عارفينه.
من ال Databases المشهورة CassandraDB و HBase
من ال Databases المشهورة CassandraDB و HBase
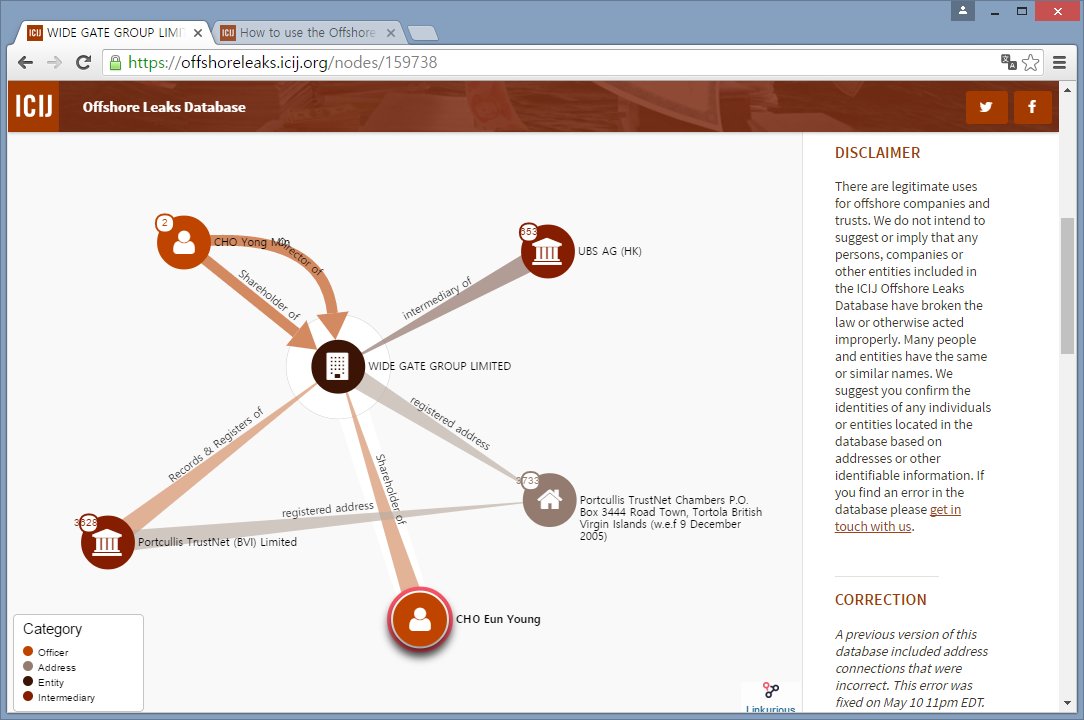
اخر نوع هو ال Graph Database، وديه نوعية قواعد بيانات بتحتفظ بالبيانات اللي الأفضل ليها تكون على شكل Graph مثلًا، ده بيبقى هدفه انك تحاول تعرف العلاقات اللي صعب توصلها بشكل البيانات الأساسي.
مثلًا قضية Panama Papers الشهيرة تم استعمال فيها ال GraphDB عشان يربطوا الخطوط ببعض.
مثلًا قضية Panama Papers الشهيرة تم استعمال فيها ال GraphDB عشان يربطوا الخطوط ببعض.
bitnine.net
من اشهر ال GraphDB واللي تقريبًا لها معظم ال Market Share هي ال neo4j
من اشهر ال GraphDB واللي تقريبًا لها معظم ال Market Share هي ال neo4j
انا بكتب الفترة ديه محتوى بسيط على آدي هنا ولينكد ان، لو حد حابب يتابعني على لينكد ان ويقرأ الموضوع من هناك بالأنجليزي لو اسهله.
linkedin.com
linkedin.com
ديه speech رائعة عن قضية اوراق باناما وال GraphDB، غالبًا كانت اول حاجة اشوفها عن ال GraphDB واكتر حاجة حببتني فيها
youtube.com
youtube.com
جاري تحميل الاقتراحات...