

في الثريد ده - ثريد طويل شويه 😄 - هحاول اعمل system design لـfacebook hashtags autocomplete و اللي ممكن يكون سؤال في انترفيو او بالخطوات اللي فيه يبقي عندك خلفيه لما تيجي تشتغل علي اي feature ممكن تخططلها ازاي
في البداية خليني بس اوضح ان في الـ System design مفيش اجابات نموذجيه و الاجابات بتختلف حسب تفاصيل النظام اللي احنا هنعمله و ان لو حاجه بس صغيره اتغيرت ف المعطيات ممكن تغير التصميم كله.
بالتالي الكلام اللي انا هقوله ده من خبرتي الشخصية و مذاكرتي و التجارب اللي عملتها في شغلي. ومش حاجه اكيده و تثق فيها. ممكن تعمل سيرش عن اي نقطه هتتقال و تتاكد ايه الحلول الصحيحه اللي ممكن تتعمل.
في البداية محتاجين نعرف ايه هو الـ hashtag .. و بشكل مختصر هي بتبقي كلمه واحده (قد تحتوي عدة كلمات و بيتم الفصل بينهم بعلامة _ ) لكن في النهاية هي كلمه واحدة. ولازم تبدا بـ# و بنقدر من خلال الهاشتاج نعرض كل الposts اللي تم ذكره فيها.
ف نقدر نقول ان الهدف من النظام اللي هنعمله هو تسجيل الـ hashtags اللي بيتم استخدامها علشان بعد كدا اليوزر لما يكتب اي هاشتاج نقدر من خلال اول ٣ احرف مثلا نعمل autocomplete من الهاشتاجز اللي موجودة عندنا و ممكن يتم ترتيبهم حسب الاكثر ذكرا بحيث اننا نعرض ال trends الاول.
ف الـFunctional Requirements: ان المستخدم هيبدا يكتب هاشتاج و السيرفس بتاعتنا المفروض ترجعله اعلي ١٠ هاشتاج مستخدمه من اول كام حرف هيكتبهم
و الـNon-function Requirements: ان نتائج البحث المفروض تظهر real time في مده اقصاها 200ms.
و الـNon-function Requirements: ان نتائج البحث المفروض تظهر real time في مده اقصاها 200ms.
هنا المشكلة اللي بنحاول نحلها هي ان عندنا كلمات كتير محتاجين طريقة تخزين فعالة جداً للبحث و العرض في مده زمنيه قليله جداً. خصوصا ان طريقة البحث هي اننا هنجيب الكلمات اللي بتبدا بنفس ال prefix اللي هيكتبه اليوز ومش هنبحث من نصف الكلمه او اخرها (خلينا نعتبر ان ده المطلوب).
ف لو عندي كلمات زي cap, captain, capital. و اليوزر كتب "ca" المفروض نعرض cap, captain, capital.
و علشان هيبقي عندي عمليات بحث كتيرة جدا. ف الاعتماد علي داتابيز فقط مش افضل حل لان الdatabase بتعمل عمليات اكتر من بكتير من مجرد عرض الكلمات بالprefix. و خصوصا اننا عاوزين نعمل index للكلمات في ال memory علشان نقدر نعمل العمليات عليها بسرعه كبيرة
هنا من انسب الـData structures اللي ممكن نستخدمها هي ال Trie. واللي بتقسم الكلمات فيها لاجزاء بنسميها nodes. وكل node بيكون فيه الحرف و list of references للحروف اللي بعده بالشكل اللي في الصورة ده
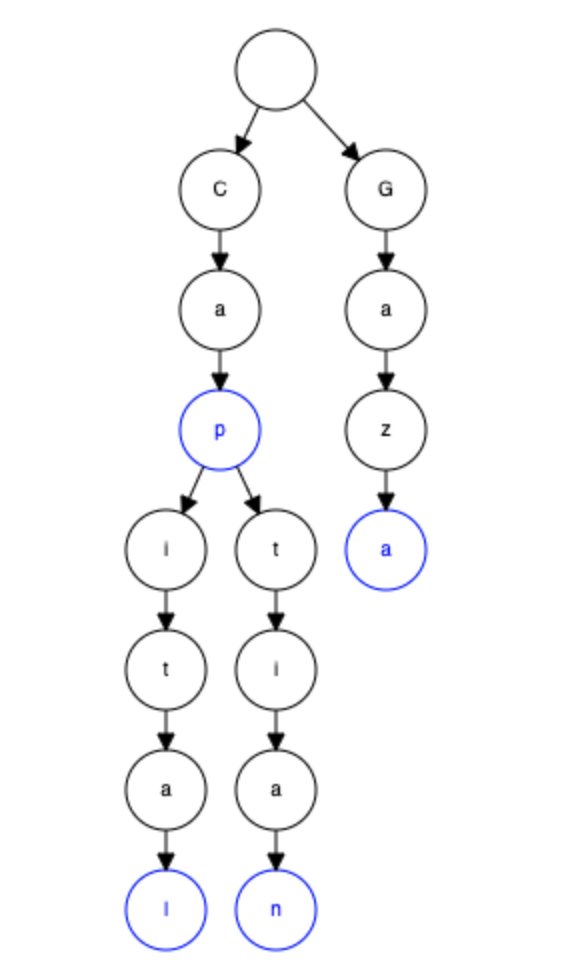
زي ما في الصورة عندك cap, captain, capital بيتشاركو في نفس ال cap prefix. في حين مثلا ان Gaza منفصله في list of nodes منفصله تماماً. واول node فاضيه دي بتكون الroot اللي بنبدا نبحث منها عن اي prefix.
والدائره الزرقاء بتعبر ان عن دي نهايه الكلمه
والدائره الزرقاء بتعبر ان عن دي نهايه الكلمه
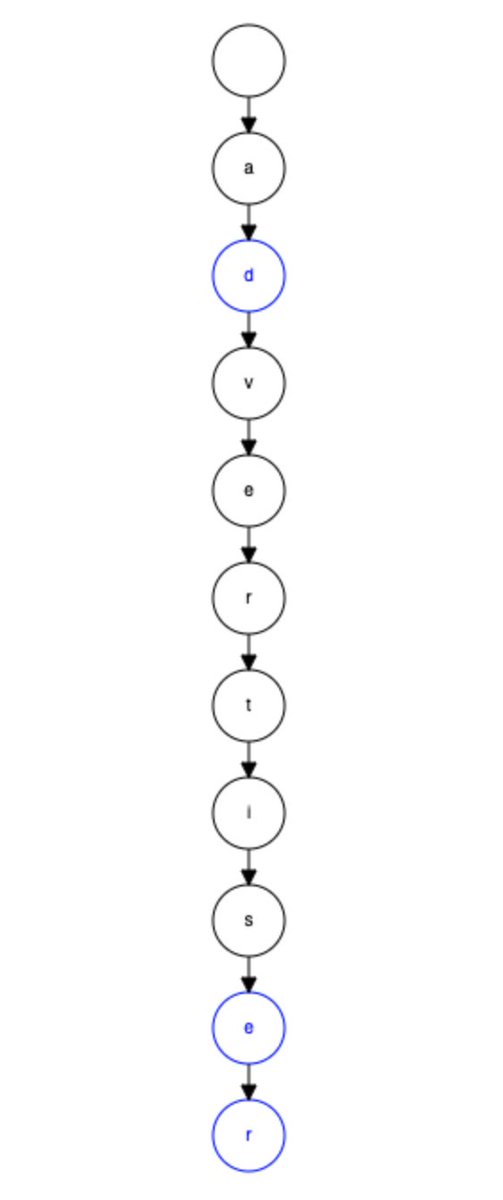
ف لو قولنا مثلا عندنا ad, advertise, advertiser هيبقي شكلهم كدا. و بكدا احنا بنوفر في تكرار الحروف و بنقدر نعرف عدد الكلمات اللي بتتشارك في نفس الحروف دي. ممكن تعمل سيرش علي Trie data structure علشان تفهمها اكتر.
ف الخلاصه هنا اننا لقينا ال DataStructure المناسبه للي احنا عاوزين نعمله. لغاية هنا فيه شوية اسئله محتاجين نسالهم و نرد عليهم اثناء النقاش
هل محتاجين نهتم بان البحث يكون case sensitive؟ غالبا هيكون لا. لان الهاشتاجز مش محتاجين نفرق فيها بين حالها الحروف. Gaza زي GAZA زي gaZA.
هل محتاجين نهتم بان البحث يكون case sensitive؟ غالبا هيكون لا. لان الهاشتاجز مش محتاجين نفرق فيها بين حالها الحروف. Gaza زي GAZA زي gaZA.
ازاي نعرض ال top suggestions؟ احد الحللول اننا نسجل hits count في كل مره يتم البحث فيها عن الكلمه.. و هنسجل العدد ده في اخر node للكلمه (الدائرة الزرقاء) بالشكل ده كل مره نعمل بحث نقدر نرتب النتائج بالcount وبكدا نعرض ال top hits.
سرعة الرد عند البحث عن prefix هكون كام؟ علي حسب حجم البيانات اللي هيتم تخزينها من المتوقع ان هيكون عندنا huge tree من ال nodes اللي هنبحث فيها. بالتالي احنا محتاجين طريقه فعالة لعرض البيانات - هنتكلم عن ده كمان شويه -.
طب ما احنا ممكن نسجل ال top hits مع كل node؟ ده اكيد حل هيكون سريع جدا للبحث و لكن مكلف جدا من حيث تخزين البيانات. لاننا بالشكل ده هنكرر الكلمات اللي ممن نرجعها لليوزر مع كل بحث. بس ممكن نخزن reference للكلمه بدل الكلمه نفسها و ده هيقلل ال space و هيكون سريع.
ازاي ممكن نبني ال Trie DS في الميموري؟ ممكن نبدا البيانات bottom up approach وده هيساعدنا اننا نعرف الtop words و اللي منها لما نوصل للـ parent node نخزن فيها الtop 10. بالشكل ده عملنا ال processing مره واحده علشان يبقي عندنا Trie نقدر نستخدمها في البحث و النتائج بالشكل المطلوب.
ازاي ممكن نعمل update للـ Trie ؟ بافتراض ان هيكون عندنا ٥ مليار ريكوست ف اليوم. يعني ٦٠ الف ريكوست ف الثانيه. ف احنا مش هنقدر نعمل update لل Trie مع كل ريكوست لان ده هيحتاج ريسورسيز كتيييييره جدا، و هياخد وقت كتير جدا.
في حين اننا ممكن نعمل التحديث offline و تبقي كل ساعه مثلا او الرقم اللي هنشوفه مناسب اثناء الشغل. بس حالياً كل ساعه. و علشان نعمل كدا ممكن نـ log كل ريكوست و نبدا نعمل عليهم عمليات بعد كدا علشان نطلع الكلمات و نعرف عددهم و نعمل update للـ trie وقتها.
ممكن نستخدم الـMapReduce -مجربتهاش قبل كدا😄- علشان نشتغل علي الlogs و يبقي عندنا الكلمات اللي محتاجه تتحدث. بعدين ناخد snapshot من الTrie و نعملها تحديث و بعدين نبدلها مع الlive trie. و بكدا يبقي كل ساعه عندنا الـ Trie محدثه و نقدر نشوف الtop hits بمجرد البحث.
تحديث الsnapshot ممكن يتم بردو باننا يكون عندنا primary and secondary للـ Trie. نعمل للـupdate secondary و نخليه primary و اللي كان primary نعمله update و نخليه secondary.
ازاي نحذف كلمه من ال Trie - لاسباب قانونية او اخلاقية او حتي تافهه -؟
ممكن يبقي عندنا list بكلمات ممنوعه و مع كل update للـtrie نتاكد اننا بنشيل الكلمات دي
وممكن بردو نعمل filtering layer علي الservice بحيث ان لو فيه اي كلمه ممنوعه متظهرش لليوزر
ممكن يبقي عندنا list بكلمات ممنوعه و مع كل update للـtrie نتاكد اننا بنشيل الكلمات دي
وممكن بردو نعمل filtering layer علي الservice بحيث ان لو فيه اي كلمه ممنوعه متظهرش لليوزر
هل ممكن نعتمد علي طريقه تانيه للranking؟ ممكن ندخل في الحسبه المكان بتاع اليوزر، اللغه بتاعته. مثلا تريند ف الصين مش لازم اكيد يظهر في مصر. او لو نفس نفس اللغه مش لازم تريند امريكا يظهر ف انجلترا.
طيب هنخزن البيانات ازاي في حاله ان السيرفر حصله restart -؟
هنا المقصود بالتخزين هي ال data persistence و اننا نحفظها علي الهارد. لانه بما اننا بنخزن الTrie في الميموري ف لما يحصل ريستارت للسيرفر البيانات دي كلها هتروح.
هنا المقصود بالتخزين هي ال data persistence و اننا نحفظها علي الهارد. لانه بما اننا بنخزن الTrie في الميموري ف لما يحصل ريستارت للسيرفر البيانات دي كلها هتروح.
فـ زي ما بنعمل update كل ساعه ممكن ناخد snapshot من الproduction trie و نعملها serialize لـ string بيمثل شكل الtree و بعدين لما نقوم اي سيرفر جديد نعمل deserialize لل string ده ف هيبقي عندنا ال trie جاهز.
و ممكن نستخدم نفس طريقة Redis في التخزين خصوصا ان عندهم اكتر من طريقة.
و ممكن نستخدم نفس طريقة Redis في التخزين خصوصا ان عندهم اكتر من طريقة.
طيب بالنسبة للـ scale .. هنظبطها ازاي؟
بافتراض اننا بنتكلم علي hashtags autocomplete لـ facebook ف ممكن نتفرض ان هيكون عندنا ٥ مليار ريكوست ف اليوم. يعني ٦٠ الف ريكوست ف الثانيه. هنفترض ان ٢٥٪ منهم unique و الباقي عمليات بحث مكرره.
بافتراض اننا بنتكلم علي hashtags autocomplete لـ facebook ف ممكن نتفرض ان هيكون عندنا ٥ مليار ريكوست ف اليوم. يعني ٦٠ الف ريكوست ف الثانيه. هنفترض ان ٢٥٪ منهم unique و الباقي عمليات بحث مكرره.
ف احنا ممكن نهتم باننا نظبط الindex لـ 50% من عمليات البحث بافتراض انها الاعلي قيمه و نهمل الباقي. ف تعالي نقول ان هيكون عندنا ١٠٠ مليون هاشتاج هنعملهم indexing.
لو افترضنا ان متوسط الهاشتاج الواحد هيكون عباره عن ٣ كلمات، كل كلمه ٥ حروف. مفصول بينهم ب_. ف حجم الهاشتاج الواحد هيكون 17 byte. و قولنا عندنا ١٠٠ مليون هاشتاج يعني ١٠٠ مليون x ١٧ يساوي مليار و ٧٠٠ بايت يعني حوالي 1.8 جيجا بايت.
يعني سيرفر بميموري ٢ جيجا هيظبطلنا الدنيا.
يعني سيرفر بميموري ٢ جيجا هيظبطلنا الدنيا.
بس ده كدا في اليوم الواحد. لو افترضنا اننا هنحذف الهاشتاجز اللي هتقدم و بافتراض معدل زياده 5% يومياً ف احنا بنتكلم في السنه كلها هتكون
1.8GB + (0.05* 1.8 * 365 ) = 35 GB
يعني ب ٤٠ جيجا بايت هنقدر من خلاله نغطي السنه كلها.
1.8GB + (0.05* 1.8 * 365 ) = 35 GB
يعني ب ٤٠ جيجا بايت هنقدر من خلاله نغطي السنه كلها.
بالرغم من ان ٣٥ جيجا رقم صغير و يقدر يكون علي سيرفر واحد. الا انه علشان نحقق الـ availability, higher efficiency and lower latencies ف احنا ممكن نعمل partition للداتا دي علي اكتر من سيرفر. فيه طرق كتير علشان نعمل كدا بس هكتفي بذكر ال partition based on hash function of the term.
فكره الHash Function اننا نقدر نحول الterms لـ رقم و يكون الرقم ده اقصاه هو عدد السيرفرات المستخدمه للتخزين. في الحاله دي مهما زودنا عدد السيرفرات علشان تخزن بيانات اكتر ال hash function هتقدر تقسم الكلمات علي السيرفرات اللي عندنا و توزعهم.
اول مشكله هنا ان كل مره هنكبر فيها عدد السيرفرات ف معظم (كل) الهاشتاجز اماكنها هتتغير ف هنضطر نخزنها من تاني.
و تاني مشكله ان ممكن تلاقي اغلب الهاشتاجز ما بين حرف A-G مثلا و باقي الحروف لغايه Z قليله.. ساعتها هيبقي عندك Nodes مليانه ع الاخر و nodes تانيه فاضيه و فيها مساحه.
و تاني مشكله ان ممكن تلاقي اغلب الهاشتاجز ما بين حرف A-G مثلا و باقي الحروف لغايه Z قليله.. ساعتها هيبقي عندك Nodes مليانه ع الاخر و nodes تانيه فاضيه و فيها مساحه.
علشان نحل المشكله باقتراح @mtantawy, ممكن نعمل hardcoded grouping بحيث نحط حروف فيها hashtags كتير مع حروف فيها hashtags قليلين عشان نوازن بين عدد ال hashtags بين المجموعات على قدر المستطاع
وبما اننا بنعمل update للـ Trie كل ساعه ف احنا ممكن نعمل cache للـ search results خلال الساعه دي بحيث اننا نوفر وقت كبير في ال aggregations و ده بالطبع هيقلل ال latency و هيرد ب يresponse time اسرع.
بما اننا هنوزع ال Trie data علي servers حسب الـ Hash function. ف احنا ممكن نعمل replication لكل shard و بالتالي لو اي shard حصل فيه مشكله الـ secondary instance من نفس الshard تقدر تاخد مكانه و تديلنا نفس الdata لغايه ما نصلح الshard اللي باظ و يبقي secondary.
ولو قولنا هنعمل high level architecture ف ممكن نقول انه هيبقي بالشكل ده
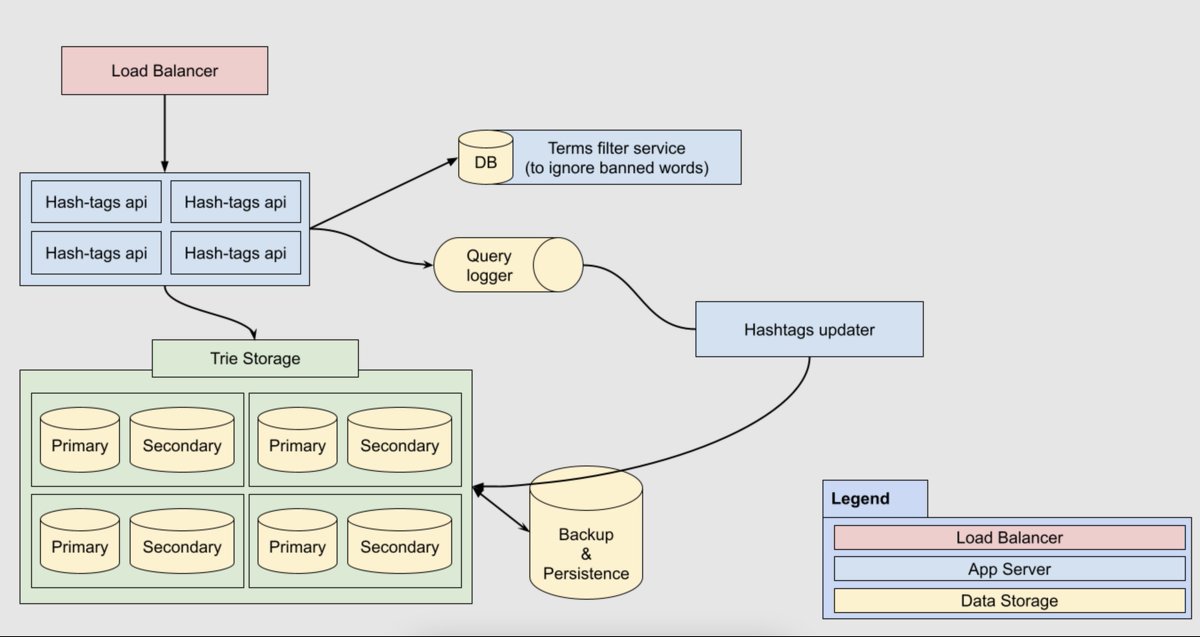
نقول كفايه لغايه هنا. فيه حاجات ممكن اكون مقولتهاش او حاجات انت شايفها مش مناسبه. طبيعي خبرتك تكون اكتر مني و شايف ان فيه اخطاء كتير ف الكلام ده. بس الفكره ان الـsystem design مفيهوش حاجه صح و غلط. كلها tradeoffs و حسب المتطلبات.
بردو في الsystem design interview الهدف منها النقاش و نقعد نطلع حاجات ف السيستم و نشوف انت ممكن تحلها ازاي او طريقه تفكيرك هتتغير ازاي حسب تغيير المتطلبات. هل هتعرف تفكر في حلول و تناقشها. ولا هتقول معرفش. ولا هتستخدم حاجه واحده لكل موقف. و اشياء اخري.
لو عاوز تتعلم الـsystem design ف انا برشحلك اللينك ده [educative.io](educative.io) و اللي انا اتعلمت و اقتبست منه اغلب الكلام اللي مكتوب هنا خصوصا "Design typehead suggestion" و اكيد هتلاقي كتب و فيديوهات لو بحث تفيدك اكتر.
جاري تحميل الاقتراحات...