

مقال جميل عن الجيل القادم للذكاء الاصطناعي حيث يتوقع ان تكون في ٣ مواضيع
١) التعلم الغير موجه
٢) التعلم المتحد
٣) نماذج الtransformers
اصفها في عجالة هنا 👇🏽
(طبعاً المقال يمثل رأي الكاتب ولكن اعجبني استناده في توقعاته الى توجهات الابحاث وآراء الخبراء)
forbes.com
١) التعلم الغير موجه
٢) التعلم المتحد
٣) نماذج الtransformers
اصفها في عجالة هنا 👇🏽
(طبعاً المقال يمثل رأي الكاتب ولكن اعجبني استناده في توقعاته الى توجهات الابحاث وآراء الخبراء)
forbes.com
*التعلم الغير موجه*
معظم نماذج الذكاء الاصطناعي اليوم هي احد انواع التعلم الموجه(supervised learning) والتي تعتمد على مجموعة بيانات معلّمة تم اضافة العلامات المرجعية لها حتى يستطيع النموذج التعلم منها
وتعليم البيانات عملية مكلفة جدا وتتطلب الكثير من الوقت
معظم نماذج الذكاء الاصطناعي اليوم هي احد انواع التعلم الموجه(supervised learning) والتي تعتمد على مجموعة بيانات معلّمة تم اضافة العلامات المرجعية لها حتى يستطيع النموذج التعلم منها
وتعليم البيانات عملية مكلفة جدا وتتطلب الكثير من الوقت
*يتبع التعلم الغير موجه*
كمثال من عملي في @nvidia، لتعليم الصور المستخدمة في نماذج السيارات ذاتية القيادة وظفت الشركة حدود الف شخص لتعليم ملايين الصور شهرياً
وبالتالي تطوير نماذج لا تعمتد على البيانات المعلّمة له اثر كبير بسبب قدرة هذه النماذج على التنبؤ بدون علامات مرجعية
كمثال من عملي في @nvidia، لتعليم الصور المستخدمة في نماذج السيارات ذاتية القيادة وظفت الشركة حدود الف شخص لتعليم ملايين الصور شهرياً
وبالتالي تطوير نماذج لا تعمتد على البيانات المعلّمة له اثر كبير بسبب قدرة هذه النماذج على التنبؤ بدون علامات مرجعية
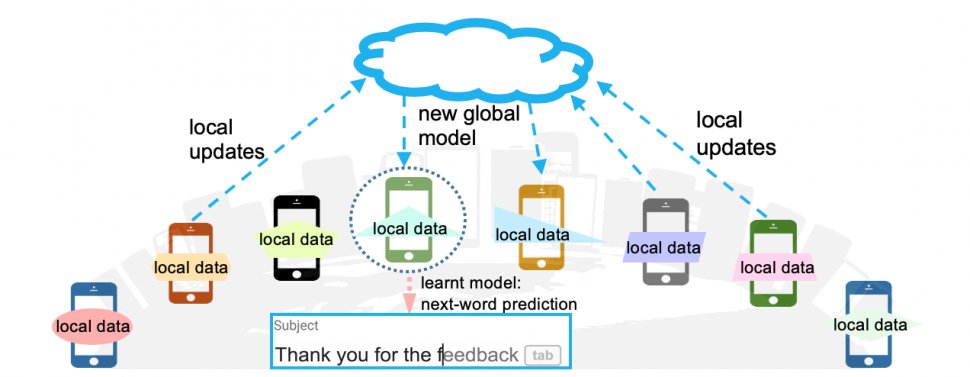
*التعلم المتحد (Federated learning)*
معظم نماذج اليوم تعتمد على حصر جميع بيانات التدريب في مكان واحد وهذا يشكل تحدي بسبب خصوصية البيانات وكثرتها وانتشارها
وبالتالي قامت قوقل بايجاد طريقة لتجاوز هذا التحدي في ٢٠١٧ عرفت بالتعلم المتحد
معظم نماذج اليوم تعتمد على حصر جميع بيانات التدريب في مكان واحد وهذا يشكل تحدي بسبب خصوصية البيانات وكثرتها وانتشارها
وبالتالي قامت قوقل بايجاد طريقة لتجاوز هذا التحدي في ٢٠١٧ عرفت بالتعلم المتحد
*يتبع التعلم المتحد*
الفكرة هي تطوير عدة نماذج مصغرّة بشكل موزّع (في الجوال مثلاً) على جزء من البيانات ثم جمع النماذج المتعددة فقط دون البيانات في مكان واحد لتشكيل نموذج اكبر منها
وبالتالي يصبح لدينا نموذج مبني على مجموعة البيانات الكاملة بدون جمع كل البيانات في مكان واحد
الفكرة هي تطوير عدة نماذج مصغرّة بشكل موزّع (في الجوال مثلاً) على جزء من البيانات ثم جمع النماذج المتعددة فقط دون البيانات في مكان واحد لتشكيل نموذج اكبر منها
وبالتالي يصبح لدينا نموذج مبني على مجموعة البيانات الكاملة بدون جمع كل البيانات في مكان واحد
*نماذج الtransformer*
وهي نماذج ذات معمارية ساعدت على معالجة البيانات بشكل متوازي عوضاً عن معالجتها بالتسلسل
وهذا بدوره جعل كفاءة تدرب هذه النماذج اعلى بشكل كبير واكبر دليل على ذلك تطوير نموذج GPT-3 والتي تم تدريبه على ٥٠٠ مليار كلمة!
وهي نماذج ذات معمارية ساعدت على معالجة البيانات بشكل متوازي عوضاً عن معالجتها بالتسلسل
وهذا بدوره جعل كفاءة تدرب هذه النماذج اعلى بشكل كبير واكبر دليل على ذلك تطوير نموذج GPT-3 والتي تم تدريبه على ٥٠٠ مليار كلمة!
في الختام، اهم ملاحظة من المقال هو اعتماد كل المواضيع على البيانات
اما من حيث الاستفادة من البيانات الغير معلّمة او البيانات المنتشرة التي يصعب الوصول اليها او من خلال تطوير قدرة النماذج على الربط بين الانماط المختبئة في اكبر قدر من البيانات
ما سموه علم البيانات من فراغ 😉
اما من حيث الاستفادة من البيانات الغير معلّمة او البيانات المنتشرة التي يصعب الوصول اليها او من خلال تطوير قدرة النماذج على الربط بين الانماط المختبئة في اكبر قدر من البيانات
ما سموه علم البيانات من فراغ 😉
جاري تحميل الاقتراحات...