

يقضي علماء البيانات من 60 الى 80% من وقتهم في تنظيف وتجهيز البيانات.
في هذا الثريد استعرض معكم تدوينة رائعة عن المهام والتحديات التي يقوم بها الفريق لتجهيز البيانات قبل بناء نماذج تعلم الآلة عرضها.
في هذا الثريد استعرض معكم تدوينة رائعة عن المهام والتحديات التي يقوم بها الفريق لتجهيز البيانات قبل بناء نماذج تعلم الآلة عرضها.
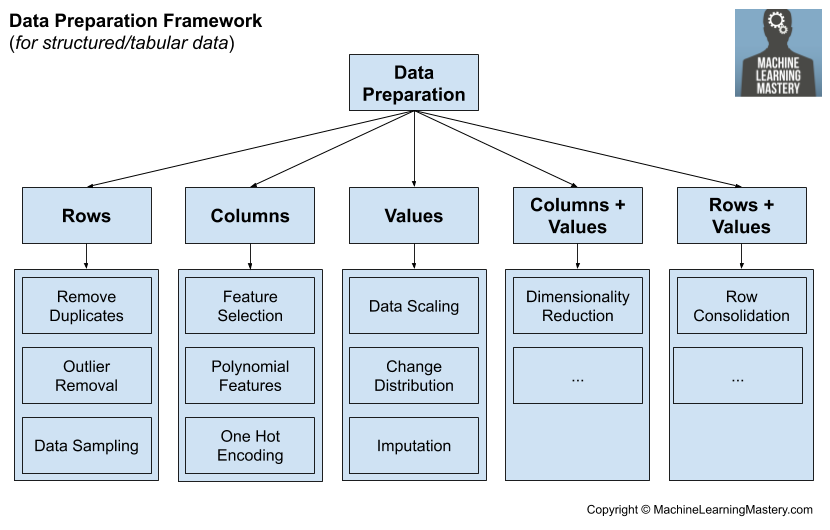
تجهيز البيانات هو تحويل البيانات الخام إلى شكل أكثر ملاءمة للنمذجة التنبؤية.
وهو مطلوب لأن البيانات نفسها تحتوي على أخطاء أو شكل أو توزيع مختلف عن ما تنتظره منك الخوارزميات المختارة.
وهو مطلوب لأن البيانات نفسها تحتوي على أخطاء أو شكل أو توزيع مختلف عن ما تنتظره منك الخوارزميات المختارة.
ولكون هذا التحدي معقد يجب التفكير في تقنيات إعداد البيانات بطريقة منهجية (مرتبة).
على سبيل المثال ، تتكون بيانات تعلُّم الآلة المنظمة (مثل البيانات التي قد نخزنها في ملف CSV للتصنيف والنماذج الخطية)، على التالي:
1- صفوف
2- أعمدة
3- قيم
لذا يتم العمل على كل هذه المستويات.
على سبيل المثال ، تتكون بيانات تعلُّم الآلة المنظمة (مثل البيانات التي قد نخزنها في ملف CSV للتصنيف والنماذج الخطية)، على التالي:
1- صفوف
2- أعمدة
3- قيم
لذا يتم العمل على كل هذه المستويات.
أولا نبدأ بتقنيات معالجة الصفوف,
هذه المجموعة مخصصة لتقنيات إعداد البيانات التي تضيف صفوف البيانات أو تزيلها.
غالبًا ما يُشار إلى الصفوف في تعلم الآلة بالعينات أو الأمثلة أو الحالات.
هذه المجموعة مخصصة لتقنيات إعداد البيانات التي تضيف صفوف البيانات أو تزيلها.
غالبًا ما يُشار إلى الصفوف في تعلم الآلة بالعينات أو الأمثلة أو الحالات.
غالبًا ما تُستخدم تقنيات معالجة الصفوف لزيادة مجموعة بيانات تدريبية محدودة (training set) أو لإزالة الأخطاء أو الغموض من مجموعة البيانات الحالية.
ومنها تقنيات إعداد البيانات التي غالبًا ما تستخدم للتصنيف غير المتوازن (imbalanced classification).
ومنها تقنيات إعداد البيانات التي غالبًا ما تستخدم للتصنيف غير المتوازن (imbalanced classification).
أهم هذه التقنيات تسمى SMOTE التي تنشئ صفوفًا اصطناعية في بيانات التدريب للتصنيفات الناقصة أو المتعرضة لاختزال عشوائي.
ويوجد لها مكتبه في بايثون تجدون تفاصيلها في هذا المقال الرائع على الرابط.
machinelearningmastery.com
ويوجد لها مكتبه في بايثون تجدون تفاصيلها في هذا المقال الرائع على الرابط.
machinelearningmastery.com
كذلك مكتبة بايثون تحتوي على تقنيات أكثر تقدما لتحديد القيم المتطرفة (outliers) وإزالتها من البيانات.
للمزيد حول إزالة القيم المتطرفة راجع الرابط
machinelearningmastery.com
للمزيد حول إزالة القيم المتطرفة راجع الرابط
machinelearningmastery.com

ثانيا: معالجة الأعمدة وغالبا سنحتاج إزالة أعمدة أو اضافة أعمدة جديدة,
في نماذج تعلم الآلة تسمى المتغيرات أو الصفات (Features).
في نماذج تعلم الآلة تسمى المتغيرات أو الصفات (Features).
ويتضمن العمل عليها تحديد علاقة هذه المتغيرات بالمدخلات ومدى تأثرها وعلاقتها ببعضها ومن ثم تحديد أهمية كل عمود.
وسيكون نتيجتها تقليل تعقيد (أبعاد) مشكلة التنبؤ أو فك متغيرات الإدخال المركبة لعدة أعمدة أو فهم الروابط بين الصفات.
وسيكون نتيجتها تقليل تعقيد (أبعاد) مشكلة التنبؤ أو فك متغيرات الإدخال المركبة لعدة أعمدة أو فهم الروابط بين الصفات.
في بايثون هناك (Recursive Feature Elimination) لغرض حذف بعض الاعمده,
أما ما يخص إضافة أعمده جديدة هناك Polynomial Feature Transforms وتوجد في بايثون أيضا باسم PolynomialFeatures.
أما ما يخص إضافة أعمده جديدة هناك Polynomial Feature Transforms وتوجد في بايثون أيضا باسم PolynomialFeatures.
ثالثا: تجهيز القيم وتغييرها,
يوجد تقنيات كثيرة لتغيير القيم ومعالجها منها التطبيع (normilization) و التوحيد القياسي للبيانات لجعلها متسقة (standrization) مثل توحيد صيغة التاريخ والعمر الخ.
وبالطبع كل ما كانت رقميه كان أفضل لخوارزمية تعلم الآلة.
يوجد تقنيات كثيرة لتغيير القيم ومعالجها منها التطبيع (normilization) و التوحيد القياسي للبيانات لجعلها متسقة (standrization) مثل توحيد صيغة التاريخ والعمر الخ.
وبالطبع كل ما كانت رقميه كان أفضل لخوارزمية تعلم الآلة.
لعملية توحيد البيانات راجع التدوينة في الرابط لمزيد من المعلومات:
machinelearningmastery.com
machinelearningmastery.com
من المهم كذلك ذكر انه يتم استخدام نماذج التنبؤ لتحديد القيم المفقوده أو الخاطئة وتوقعها وتعبيئتها من جديد لغرض إكتمال البيانات وتسمى Statistical Imputation for Missing Values
في النهاية أود أن أذكر أن هناك تقنيات أخرى أكثر تقدما تتعامل مع الصفوف والقيم معاً مثل التجميع clustering
أو الاعمدة والقيم معا مثل matrix factorization قد أكتب عنها لاحقا.
وتذكر دائما أن نجاح نموذج تعلم الآلة يعتمد إعتماد كلي على جودة البيانات المستخدمة garbage in garbage out
أو الاعمدة والقيم معا مثل matrix factorization قد أكتب عنها لاحقا.
وتذكر دائما أن نجاح نموذج تعلم الآلة يعتمد إعتماد كلي على جودة البيانات المستخدمة garbage in garbage out
جاري تحميل الاقتراحات...