

اهلاً
باتكلم عن نوع من انواع الهجمات يسمى ال HTTP Request Smuggling Attack .
في المواقع و التطبيقات الكبيرة او حتى التطبيقات الناشئة اللي تكون ال infrastructure حقتها كويسة و مبنية بشكل صحيح لتقليل التكاليف و رفع ال availability راح يكون موجود شي اسمه load balancer
باتكلم عن نوع من انواع الهجمات يسمى ال HTTP Request Smuggling Attack .
في المواقع و التطبيقات الكبيرة او حتى التطبيقات الناشئة اللي تكون ال infrastructure حقتها كويسة و مبنية بشكل صحيح لتقليل التكاليف و رفع ال availability راح يكون موجود شي اسمه load balancer
طيب وش الهدف من وجود ال load balancer ؟
الهدف منها هو توزيع ال requests على ال servers بحيث انه بدل ما يكون عندك سيرفر واحد مضغوط يكون عندك اكثر من سيرفر يتعاملون مع ال requests.
الهدف منها هو توزيع ال requests على ال servers بحيث انه بدل ما يكون عندك سيرفر واحد مضغوط يكون عندك اكثر من سيرفر يتعاملون مع ال requests.
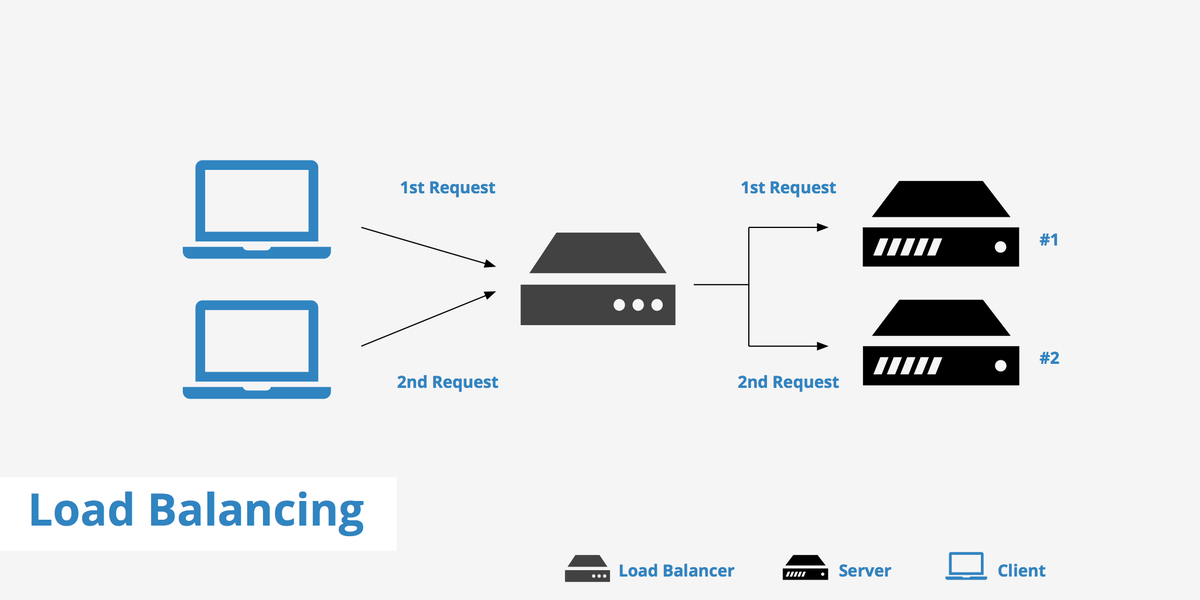
بما اننا فهمنا وش ال load balancer من هنا و طالع راح اغير التسمية الى front-end server و السيرفرات راح اسميها back-end servers عشان اللي يبحث ما يتفاجأ بالتسميات و اختلافها.
في الحالة المعتادة و الافضل من ناحية الأداء يرسل ال front-end server ال requests على اجزاء لل back-end servers و من ال HTTP headers يعرف ال back-end server وين ينتهي ال request الحالي و وين يبدا ال request الجديد
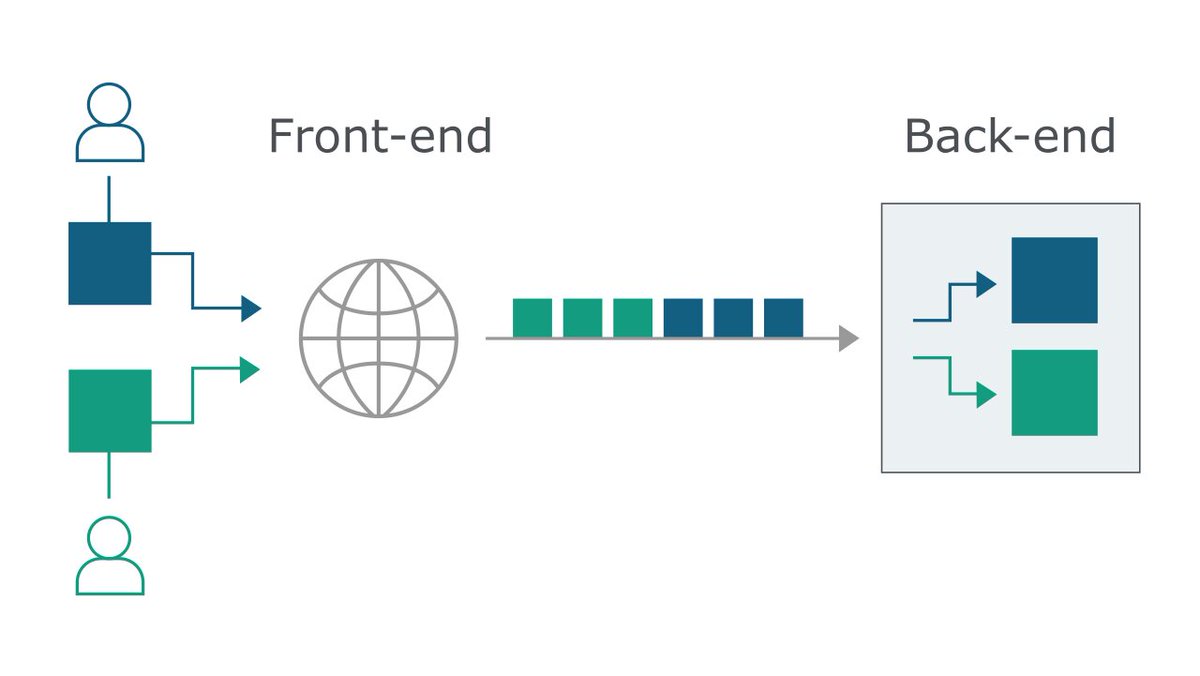
طيب وش راح يصير لما يختلفون ال front-end server و الback-end server على طول ال request ؟
يعني ال front-end server استقبل request و اعتبر طوله 200 و ارسله لل back-end server و ال back-end server اعتبر طول ال request مثلاً 100 بس ؟!
يعني ال front-end server استقبل request و اعتبر طوله 200 و ارسله لل back-end server و ال back-end server اعتبر طول ال request مثلاً 100 بس ؟!
هنا ال back-end server راح ياخذ اول 100 و يعتبرهم ال request الاول و ياخذ ال 100 الثانية و يعتبرها بداية request جديد !
في الصورة هذي يبين لك كيف الجزء الاخير من ال request حق المهاجم صار الجزء الأول من ال request لمستخدم ثاني.
في الصورة هذي يبين لك كيف الجزء الاخير من ال request حق المهاجم صار الجزء الأول من ال request لمستخدم ثاني.
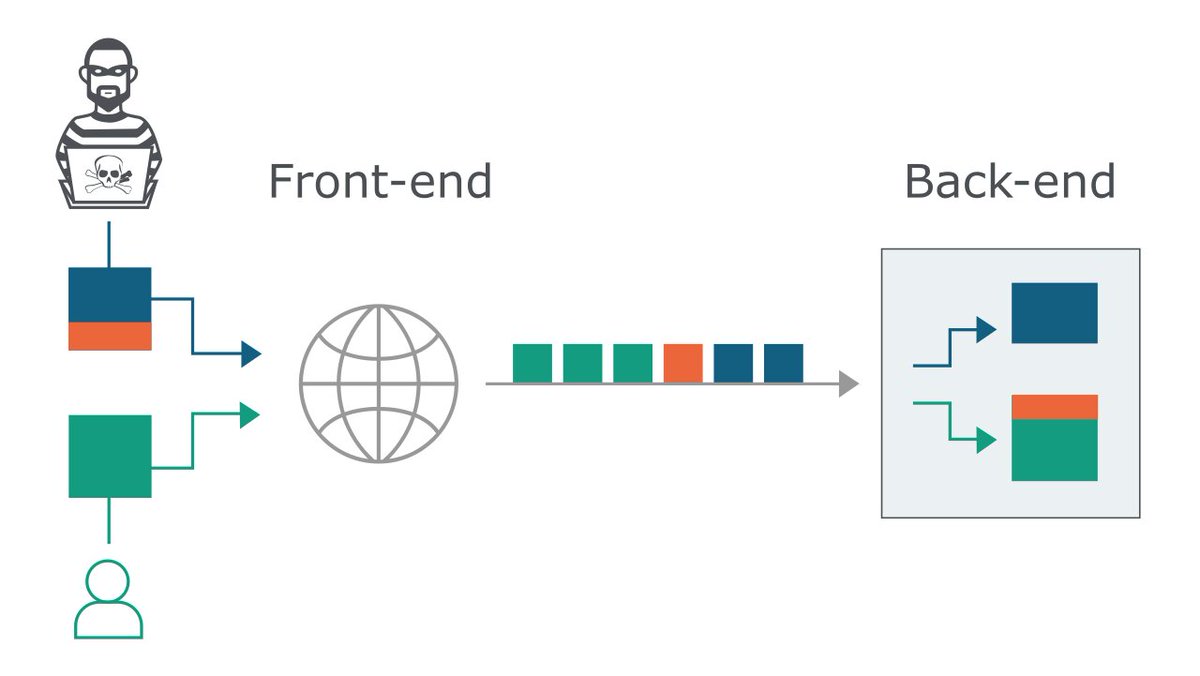
طيب كيف يتم سوء التفاهم بين ال front-end وال back-end ؟ عادةً تكون المشكلة في إن ال front-end و ال back-end يستخدمون طريقتين مختلفة في التعامل مع طول ال request ، مثلاً ال front-end يعتمد على ال header :
content-length
و ال back-end يعتمد على :
transfer-encoding: chunked
content-length
و ال back-end يعتمد على :
transfer-encoding: chunked
ال header الاول بسيط جداً ، تمرر له طول ال body بال byte مثل كذا :

اما لما نستخدم ال header الثاني الموضوع مختلف شوي لانه مثل ما قلنا يقسم ال request او تحديداً ال body الى اجزاء ، يكون عندنا الشكل التالي :
في المثال هذا :
ال b هي hexadecimal و لما تحولها بتطلع معك 11 و هو طول ال data في اول جزء
بعده ال data
بعده 0 اللي هي علامة نهاية ال body
في المثال هذا :
ال b هي hexadecimal و لما تحولها بتطلع معك 11 و هو طول ال data في اول جزء
بعده ال data
بعده 0 اللي هي علامة نهاية ال body

طيب بما اننا فهمنا طريقة حساب الطول ، خلونا نشوف كيف ممكن يتم استخدام المعلومات اللي عندنا عشان ننفذ الهجوم :
نفرض ان ال front-end server يستخدم ال content-length و ال back-end server يستخدم ال transfer-encoding: chunked
شي مثل كذا بيستغل الثغرة (as a POC)
نفرض ان ال front-end server يستخدم ال content-length و ال back-end server يستخدم ال transfer-encoding: chunked
شي مثل كذا بيستغل الثغرة (as a POC)

وش صار في ال request ؟
حددنا الطول ب 13 و بالتالي ال front-end server خذ ال request كامل و اضفنا ال transfer-encoding: chunked
الآن لما يستقبل ال front-end server ال request راح يمشيه بشكل طبيعي و كامل لل back-end server واللي بدوره راح يعتبر نهاية ال body بال 0
حددنا الطول ب 13 و بالتالي ال front-end server خذ ال request كامل و اضفنا ال transfer-encoding: chunked
الآن لما يستقبل ال front-end server ال request راح يمشيه بشكل طبيعي و كامل لل back-end server واللي بدوره راح يعتبر نهاية ال body بال 0
و يعتبر SMUGGLED اول جزء من ال request الجديد اللي راح يوصله. يعني ال request الجاي بتكون بدايته شي مثل كذا :
SMUGGLEDGET / HTTP/1.1
باعتبار ان ال method هي GET طبعاً لل request الجديد.
SMUGGLEDGET / HTTP/1.1
باعتبار ان ال method هي GET طبعاً لل request الجديد.
تقدر تقرا أكثر عن الموضوع في موقع portswigger ، و فيه labs على الثغرة و شرح لحالات اكثر ، و طبعاً الثغرة ممكن تكون موجودة في بعض الحالات حتى لو ال front-end وال back-end يستخدمون ال transfer-encoding: chunked
portswigger.net
portswigger.net
مشكلة ال HTTP Request smuggling انه صعب بالطريقة التقليدية انك تعرف اذا الهدف اللي تسوي له اختبار مصاب في حال كان عنده traffic عالي لان الإضافة اللي أضفتها لل request الجديد بتروح عند غيرك في الغالب و بالتالي تخرب على المستخدمين تجربتهم للخدمة و ما قدرت تعرف اذا الثغرة موجودة
بس ممكن تستخدم طرق ثانية تبين لك اذا كان مصاب او لا بدون ما تخرب على أحد و اكثر فاعلية من الطريقة التقليدية
راح اشرح على ال lab حق portswigger لحالة ال content length لل front-end و ال transfer-encoding لل back-end
راح اشرح على ال lab حق portswigger لحالة ال content length لل front-end و ال transfer-encoding لل back-end
بعد ما تسوي لك حساب يفترض انك تقدر تدخل صفحة ال lab هذي :
portswigger.net
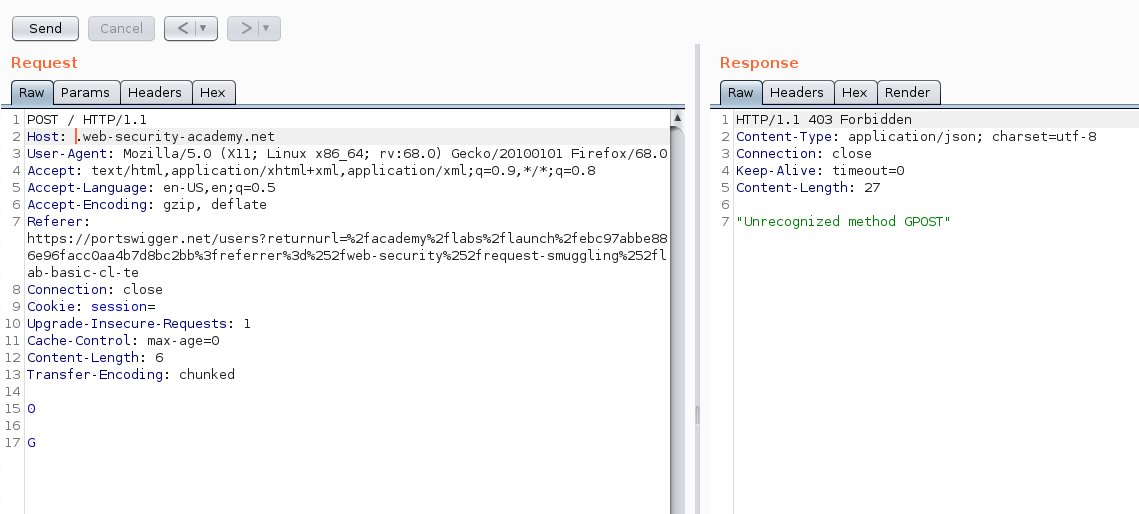
طبعاً الحل اللي هم يبغونه و التقليدي راح يرجع في ال request الثاني اللي ترسله Unrecognized method GPOST
portswigger.net
طبعاً الحل اللي هم يبغونه و التقليدي راح يرجع في ال request الثاني اللي ترسله Unrecognized method GPOST
طيب اول خطوة راح اسويها في ال lab هي اني اشغل proxy في حالتي افضل burp suite ، و اعترض الاتصال للصفحة الرئيسية و احولها لل Repeater عشان اعدل على ال request على راحتي و اكثر من مرة لو غلطت في شي و اشوف النتيجة مباشرة.
بعد اعتراض ال request و تحويله لل repeater
بعد اعتراض ال request و تحويله لل repeater
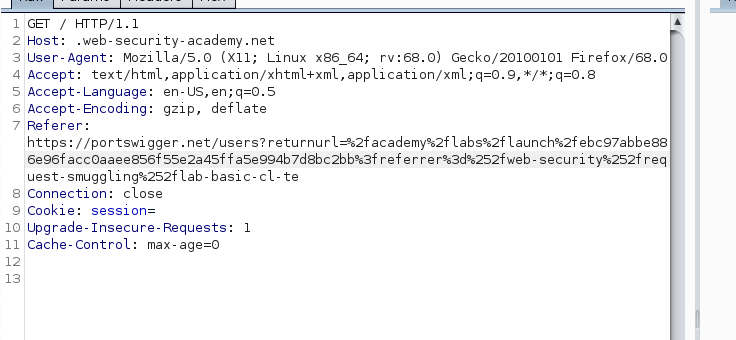
الحل التقليدي و المطلوب في ال lab هو التالي :
نضيف ال headers و بعدها نضيف ال 0 في ال body عشان ال back-end server يعتبر ال G جزء من ال request الجديد و الrequest الثاني اللي نرسله بدال ما يكون
POST / HTTP/1.1
يصير
GPOST / HTTP/1.1
نضيف ال headers و بعدها نضيف ال 0 في ال body عشان ال back-end server يعتبر ال G جزء من ال request الجديد و الrequest الثاني اللي نرسله بدال ما يكون
POST / HTTP/1.1
يصير
GPOST / HTTP/1.1
طيب انا من اليوم اقول الطريقة التقليدية ، وش البدائل ؟
فيه اكثر من حل بديل و من اشهرها يمكن انك تحاول تطلع timeout من السيرفر .
طبعاً الثغرة ممكن تسمح لك تخزن ال request الجديد (من مستخدم ثاني) و بالتالي تشوف المحتوى سواءً كان قيمة ال session او اي مدخل فعلياً ارسله المستخدم !
فيه اكثر من حل بديل و من اشهرها يمكن انك تحاول تطلع timeout من السيرفر .
طبعاً الثغرة ممكن تسمح لك تخزن ال request الجديد (من مستخدم ثاني) و بالتالي تشوف المحتوى سواءً كان قيمة ال session او اي مدخل فعلياً ارسله المستخدم !
تقدر تشوف شرح للثغرة مع بعض ال case studies و طرق غير الطريقة التقليدية لل detection و خطورة الثغرة في الفيديو هذا :
youtube.com
youtube.com
و بس والله خلصت سواليفي 😅
جاري تحميل الاقتراحات...