

جاءني مبتهجاً يقول: لقد نجحت في بناء مودل باستخدام خوارزميات الـ Machine Learning بلغت دقته 99% ، فقلت له: لقد وقعت في فخ الـ "overfitting" .. فنظر أليّ وقال: وما الـ "overfitting"؟...
لكم و له أشرح أسفل هذه التغريدة مشكلة الـ overfitting وكيف نتفاداها؟
لكم و له أشرح أسفل هذه التغريدة مشكلة الـ overfitting وكيف نتفاداها؟
حتى نقرب الصورةونوضح المعنى بدون الدخول في دهاليز التقنيةومصطلحاتها المعقدة،دعونانتعرف على قصةحازم وسامح مدرسا الرياضيات في إحدى المدارس الثانوية،وكيف أن حازم نجح في جعل تحصيل طلابه عالي في اختبارالقدرات بعكس سامح والذي كان تحصيل طلابه منخفض رغم حصولهم على درجات مرتفعةفي الثانوية
كان الطلاب عند حازم يحصلون على درجات منخفضة في اختبار الرياضيات بالثانوية بمتوسط 80% مقارنة مع طلاب سامح والذي وصل تحصيلهم في المتوسط إلى 98% ، لذا كان اولياء أمور الطلاب يحرصون بشكل كبير على أن يدرس أبنائهم مع سامح حتى يحصلون على درجات مرتفعة في الثانوية
مع الوقت أكتشف اولياء الأمور أن تحصيل طلاب حازم مرتفع في اختبار القدرات مقارنةمع التحصيل المنخفض لطلاب سامح،هنا طرحوا سؤال:لماذا تحصيل طلاب سامح في القدرات منخفض (65%) رغم تحصيلهم العالي في الثانوية (98%)
بينما طلاب حازم تحصيلهم عالي ( 85%) رغم التحصيل المنخفض في الثانوية (80%)؟
بينما طلاب حازم تحصيلهم عالي ( 85%) رغم التحصيل المنخفض في الثانوية (80%)؟
بعد البحث والتقصي ومراقبةطريقةتعليم حازم وسامح،أكتشفوا أن حازم يقوم بتدريب طلابه على مسائل عامةومتنوعةويختبرهم في مسائل جديدةيعتمد حلهاعلى الفهم، بينما سامح يعتمدفي تدريب طلابه على مسائل محددةيكتبها لهم على شكل ملخص وتأتيهم الاسئلةنصاًمن الملخص لذايعتمدون في حلهاعلى التذكر والحفظ
في القصة وقع سامح في فخ الـ overfitting وذلك "بتفصيل" تعلم طلابه على مسائل معينة بدون تدريبهم واختبارهم على مسائل جديدة ليختبر مدى تعلمهم ، بينما نجح حازم في بناء نموذج تعليمي لطلابه من خلال تدريبهم على مسائل متنوعة واختبارهم في مسائل جديدة للتحقق من مدى تعلمهم
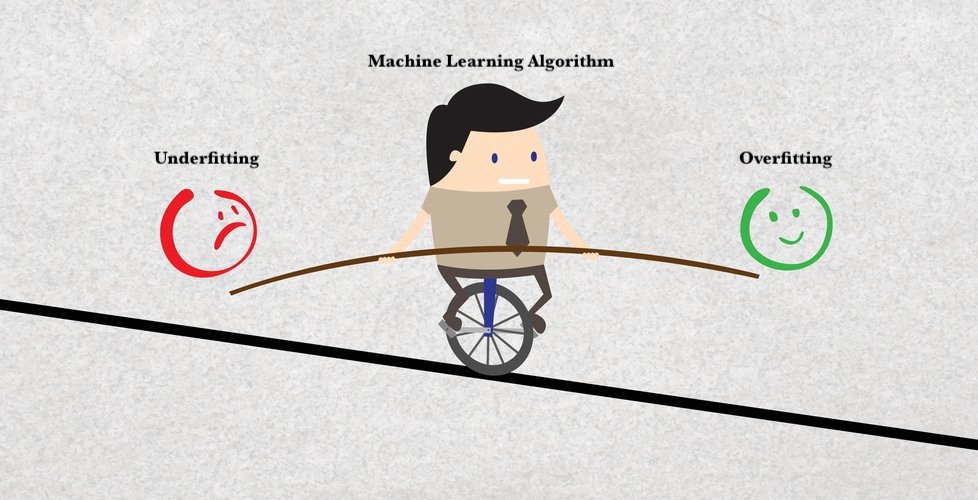
في بناء مودل باستخدام خوارزميات الـ Machine Learning يكون الهدف الـ Generalization وتعني إمكانيةتعميم المودل على البيانات التي لم تستخدم في التدريب، الوقوع في فخ الـoverfitting تعني عدم حصول التعميم وبالتالي يفشل المودل في الحصول على دقةعالية في الواقع رغم دقته العالية في التدريب
سبب الوقوع في مشكلة الـ overfitting هي استخدام نفس البيانات في تدريب المودل واختباره ، لذلك الدقة العالية التي نحصل عليها تكون بسبب ان المودل يتذكر الـ pattern وليس بسبب انه تعلم! .. من أشهر الخوارزميات التي تعاني من مشكلة الـ "overfitting" خوارزمية Decision tree
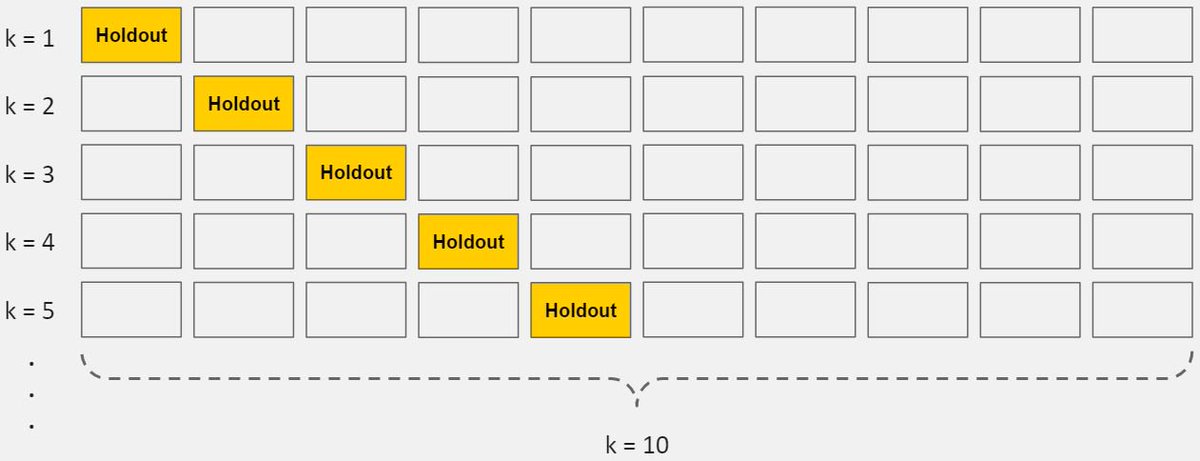
هناك عدة طرق تستخدم لتجاوز معضلة الـ overfitting لعل أشهرها وأكثرها نجاحاً cross-validation وتقوم على مبدأ حجز جزء من البيانات للاختبار وتدريب المودل على البقية ، وفي الغالب تتم بطريقة 90% من البيانات للتدريب و 10% للاختبار .. السؤال ماهي البيانات التي نحجزها؟

حتى نثق في وصولنا لحالة تعميم المودل (Generalization) ، يتم تكرار تدريب المودل واختباره 10 مرات بطريقة 90% للتدريب و 10% للاختبار ، وكل مره نغير الـ 10% ، وبالتالي نضمن اننا غطينا حالات كثيرة حينما نختبر المودل ، وتحسب دقة المودل بمتوسط العشر اختبارات
الخلاصة ، أننا في حياتنا العامة نرفض "التعميم" بحكم معين على مجتمع ما من تصرفات "بعض" أفراده ، فكيف نقوم "بتعميم" مودل اعتماداً على "بعض"البيانات التي قد لاتكون ممثلة لكل الحالات في الواقع؟.. هنا نحن نخدع الحاسب ونجعله يقع في فخ الـ overfitting .. للمزيد: elitedatascience.com
جاري تحميل الاقتراحات...